Archive for article
May 1, 2024 · category article, imagination artificielle, intelligence artificielle, [une], [video]
french //
En 1967 , Michael Snow réalise Wavelength. Un lent zoom de 45 mn dans un loft qui nous est inconnu. Lent zoom qui tend vers une image : celle de l’Océan. Le zoom peu à peu réduit le champ, amène que ce qui précède tombe dans le hors-champ. Notre mémoire dans la lecture de ces quelques mètres à travers lequel le zoom s’effectue, enregistre silencieusement chaque détail, de ce qui ne fait aucune diégèse.
Gene Youngblood décrit Wavelength comme « sans précédent dans la pureté de sa confrontation avec l’essence du cinéma : les relations entre illusion et fait, espace et temps, sujet et objet » Le film Latent space of off-screen inverse le processus.La vague surviendra mais dans le zoom arrière infini à partir d’une oeuvre de Hopper : People in the Sun.
Des convives sont allongés sur des transats, en bordure de terrasse, le long d’une bâtisse dont on ne perçoit qu’un fragment. Ils regardent vers la droite. Ils regardent en direction d’un hors-champ. Celui-ci nous est interdit définitivement. Hopper n’aura pas dit ce qu’il aurait pu ici imaginer. Notre pensée est suspendue à ce qui s’échappe de la représentation.
Nous regardons ces regardeurs, et nous sommes saisis par ce manque. C’est là, une des signatures remarquables de Hopper. Le hors-champ.
Avec une IA qui fonctionne sans prompt, donc sans un vecteur d’imagination humaine demandant de produire un motif, il s’agit d’explorer ce hors-champ, ce vide. L’IA va alors imaginer seulement à partir des pixels, le hors-champ. Mais ici il s’agit de travailler dans une exploration spatiale et temporelle comme l’a initié Michael Snow en 1967 : au lieu du zoom avant, c’est un zoom arrière infini. En contre-point a été monté du son concret.
Par ce processus il s’agit de relier le hors-champ à l’espace latent de l’imagination artificielle. Qu’est-ce qui va avoir lieu, si on laisse une IA constituer ce hors-champ. Alors que l’être humain aura tendance à imaginer un univers diégétique, aura sans doute le désir de combler la suspension du regard par une causalité, dont les regardeurs seraient alors la conséquence, l’IA va poursuivre l’image selon un processus non-événementiel : seulement pictural. L’imagination artificielle, détachée de l’intentionnalité humaine et du prompt est la saisie pure de la densité des pixels et l’intensification plastique du motif initial. Plus on s’éloigne, plus devient concret la factualité de l’IA, plus on explore l’espace latent de l’image en tant qu’image et non pas en tant que récit ou narration. La complétion ici, ne renvoie pas à la question du monde humain et du possible anthropologique, mais d’un décollement de l’imaginaire humain et de ses notions spatiales et temporelles, pour que ressortent la matérialité et la temporalité spécifique de l’IA.
// english
In 1967, Michael Snow directed Wavelength. A slow 45 minute zoom in a loft that is unknown to us. Slow zoom which tends towards an image: that of the Ocean. The zoom gradually reduces the field, causing what precedes to fall off-screen. Our memory, within these few meters through which the zoom takes place, silently records every detail, of which there is no diegesis. Gene Youngblood describes Wavelength as "unprecedented in the purity of its confrontation with the essence of cinema: the relationships between illusion and fact, space and time, subject and object." The film Latent space of off-screen reverses the process. The wave will occur but in the infinite zoom out from a work by Hopper: People in the Sun.
Guests are lying on deckchairs, at the edge of the terrace, alongside a building of which we can only see a fragment. They look to the right. They look towards someone off-camera. This is definitely forbidden to us. Hopper will not have said what he could have imagined here. Our thinking is suspended on what escapes from representation. We look at these spectators, and we are struck by this lack. This is one of Hopper’s remarkable signatures. Off-camera. With an AI that works without a prompt, therefore without a vector of human imagination asking to produce a pattern, it is a question of exploring this off-camera, this void. The AI ​​will then imagine only from the pixels, the off-camera. But here it is a question of working in a spatial and temporal exploration as initiated by Michael Snow in 1967: instead of zooming in, it is an infinite zoom out. As a counterpoint, concrete sound was produced.
Through this process it is a question of connecting the off-camera to the latent space of artificial imagination. What will happen if we let an AI constitute this off-camera. While the human being will tend to imagine a dietary universe, will undoubtedly have the desire to fill the suspension of the gaze with a causality, of which the viewers would then be the consequence, the AI ​​will pursue the image according to a non- event-related: only pictorial. Artificial imagination, detached from human intentionality and promptness, is the pure capture of the density of pixels and the plastic intensification of the initial motif. The further we move away, the more concrete the news of AI becomes, the more we explore the latent space of the image as an image and not as a story or narration.
The completion here does not refer to the question of the human world and the anthropological possibility, but of a separation of the human imagination and its spatial and temporal notions, so that the materiality and specific temporality of AI emerge.
April 29, 2024 · category article, imagination artificielle, intelligence artificielle, [une]
 L’une des caractéristiques de la peinture de Hopper, tient à la mise en tension du hors-champ à partir de la représentation picturale. Les personnages sont immobiles, souvent le regard fixe, dans un instant de temps, qui loin de se refermer sur l’intérieur du tableau, appelle le hors-champ. Que cela soit dans Cape Cod morning, dans City Sunlight, dans Morning sun : les femmes représentées, font face à des fenêtres et regardent vers un extérieur dont le spectateur est privé.
L’une des caractéristiques de la peinture de Hopper, tient à la mise en tension du hors-champ à partir de la représentation picturale. Les personnages sont immobiles, souvent le regard fixe, dans un instant de temps, qui loin de se refermer sur l’intérieur du tableau, appelle le hors-champ. Que cela soit dans Cape Cod morning, dans City Sunlight, dans Morning sun : les femmes représentées, font face à des fenêtres et regardent vers un extérieur dont le spectateur est privé.
En poursuivant la série Completion, je me suis intéressé à ce hors-champ. Il n’existera plus car Hopper est mort. On ne saura jamais ce que ces personnages regardaient. Pourquoi ils étaient ainsi pris par ce qui n’apparaît pas dans l’espace pictural.
 L’IA utilisée dans ce travail ne génère pas avec des prompts. C’est un double processus. d’IA qui a lieu : 1/ le premier est une analyse de l’image 2/ une complétion de l’image à partir de la perception artificielle . L’IA, quelque soit les fantasmes qu’on veuille lui prêter, au niveau de la génération, fonctionne par une induction statistique qui correspond donc à un champ de probabilité de concordance. C’est en ce sens qu’elle ne crée rien d’extraordinaire, mais elle se conforme à un attendu. La question serait e savoir jusque’à quel point elle se conforme. En ce sens, l’ontologie du réel de l’imagination artificielle est strictement tenu dans un déploiement logico-mathématique, même si nous avons l’impression d’une forme de liberté de création dans le processus. Ce qui est survient comme extraordinaire tient surtout à la définition du prompt (recherche à la fois du contenu – et c’est pour cela qu’il y a autant de génération surréaliste ou fantastique ou SF – et des règles de visualisation du contenu). Sans prompts, l’IA générative produit l’image qui sera la plus probable à partir de son contexte. Et de fait c’est cela qu’il faut souligner : l’IA ne créera aucun autre événement dans l’image que de poursuivre un hors-champ à partir du champ.
L’IA utilisée dans ce travail ne génère pas avec des prompts. C’est un double processus. d’IA qui a lieu : 1/ le premier est une analyse de l’image 2/ une complétion de l’image à partir de la perception artificielle . L’IA, quelque soit les fantasmes qu’on veuille lui prêter, au niveau de la génération, fonctionne par une induction statistique qui correspond donc à un champ de probabilité de concordance. C’est en ce sens qu’elle ne crée rien d’extraordinaire, mais elle se conforme à un attendu. La question serait e savoir jusque’à quel point elle se conforme. En ce sens, l’ontologie du réel de l’imagination artificielle est strictement tenu dans un déploiement logico-mathématique, même si nous avons l’impression d’une forme de liberté de création dans le processus. Ce qui est survient comme extraordinaire tient surtout à la définition du prompt (recherche à la fois du contenu – et c’est pour cela qu’il y a autant de génération surréaliste ou fantastique ou SF – et des règles de visualisation du contenu). Sans prompts, l’IA générative produit l’image qui sera la plus probable à partir de son contexte. Et de fait c’est cela qu’il faut souligner : l’IA ne créera aucun autre événement dans l’image que de poursuivre un hors-champ à partir du champ.
 C’est pour cela que cette série de Complétion s’appelle : No camera-off event. Pas d’événement hors-champ. La solitude des personnages de Hopper est ainsi renforcé. Le spectateur n’aura pas la clé du hors-champ, car l’IA poursuivant l’exploration d’un espace ne pense pas la catégorie de l’événement. Elle ne crée pas de « Il arrive ». Cette nouvelle série d’exploration de Hopper se structure tout à la fois sur la production d’images de très grand format (par exemple 16000X8000 pixels) et sur des vidéos qui mettent en tension la liaison entre le champ et le hors-champ.
C’est pour cela que cette série de Complétion s’appelle : No camera-off event. Pas d’événement hors-champ. La solitude des personnages de Hopper est ainsi renforcé. Le spectateur n’aura pas la clé du hors-champ, car l’IA poursuivant l’exploration d’un espace ne pense pas la catégorie de l’événement. Elle ne crée pas de « Il arrive ». Cette nouvelle série d’exploration de Hopper se structure tout à la fois sur la production d’images de très grand format (par exemple 16000X8000 pixels) et sur des vidéos qui mettent en tension la liaison entre le champ et le hors-champ.
// English
One of the characteristics of Hopper’s painting is the tension created off-screen based on the pictorial representation. The characters are immobile, often with a fixed gaze, in a moment of time, which far from closing on the interior of the painting, calls out to the off-camera. Whether in Cape Cod morning, in City Sunlight, in Morning sun: the women represented face windows and look towards an exterior of which the viewer is deprived. While continuing the Completion series, I became interested in this off-camera. He will no longer exist because Hopper is dead. We will never know what these characters were looking at. Why were they so taken by what does not appear in pictorial space.
The AI ​​used in this work does not generate with prompts. It is a double process. of AI which takes place: 1/ the first is an analysis of the image 2/ a completion of the image from artificial perception.
 AI, whatever fantasies we want to attribute to it, at the generation level, works by statistical induction which therefore corresponds to a concordance probability field. It is in this sense that it does not create anything extraordinary, but it conforms to an expectation. The question would be to what extent she complies. In this sense, the ontology of reality of artificial imagination is strictly held in a logical-mathematical deployment, even if we have the impression of a form of creative freedom in the process.
AI, whatever fantasies we want to attribute to it, at the generation level, works by statistical induction which therefore corresponds to a concordance probability field. It is in this sense that it does not create anything extraordinary, but it conforms to an expectation. The question would be to what extent she complies. In this sense, the ontology of reality of artificial imagination is strictly held in a logical-mathematical deployment, even if we have the impression of a form of creative freedom in the process.
 What emerges as extraordinary is mainly due to the definition of the prompt (search for both content – and this is why there is so much surrealist or fantastic or SF generation – and the rules for viewing the content). Without prompts, generative AI produces the image that will be most likely from its context. And in fact this is what must be emphasized: the AI ​​will not create any other event in the image than to pursue an off-camera from the frame. This is why this Completion series is called: No camera-off event. No off-screen events.
What emerges as extraordinary is mainly due to the definition of the prompt (search for both content – and this is why there is so much surrealist or fantastic or SF generation – and the rules for viewing the content). Without prompts, generative AI produces the image that will be most likely from its context. And in fact this is what must be emphasized: the AI ​​will not create any other event in the image than to pursue an off-camera from the frame. This is why this Completion series is called: No camera-off event. No off-screen events.
The solitude of Hopper’s characters is thus reinforced. The spectator will not have the key to the off-camera, because the AI ​​continuing to explore a space does not think about the category of the event. It doesn’t create “He’s coming.” This new exploration series by Hopper is structured both on the production of very large format images (for example 16000X8000 pixels) and on videos which tension the connection between the on-camera and off-camera.
April 22, 2024 · category article, imagination artificielle, intelligence artificielle, photographie, [théorie], [une]
// French – English below
 Notre mémoire, parfois nous le regrettons, est fragmentaire. Pendant des siècles, il n’y eut que la rétention parla conscience et ses potentialités mnésiques pour se souvenir en image d’un passé. Que l’on avait vécu, ou bien que l’on avait entendu. La photographie a changé cela. Alors que la mémoire eidétique est très rare chez l’être humain, avec la photiographie, on a pu faire des ponctions dans le réel. Regarder une photo c’est revoir un fragment (temprorel et spatial du passé) de ce qui a eu lieu.
Notre mémoire, parfois nous le regrettons, est fragmentaire. Pendant des siècles, il n’y eut que la rétention parla conscience et ses potentialités mnésiques pour se souvenir en image d’un passé. Que l’on avait vécu, ou bien que l’on avait entendu. La photographie a changé cela. Alors que la mémoire eidétique est très rare chez l’être humain, avec la photiographie, on a pu faire des ponctions dans le réel. Regarder une photo c’est revoir un fragment (temprorel et spatial du passé) de ce qui a eu lieu.
Mais il y a toujours du hors-champ. Le hors-champ c’est ce qui a échappé à la captation et la mémoire technique. On peut ainsi penser la photographie comme une prothèse technique de notre mémoire. Une extension. Cependant cette mémoire est limitée, elle est aussi fragmentaire. Elle est un segment infime de l’espace et du temps. Une portion.
Avec Complétion, il m’est apparu nécessaire d’interroger la question du hors-champ à l’ère des IA : si le hors champ de ce qui a été mémorisé est ce qui a disparu, que je ne peux qu’imaginer, comment peut-il être abordé et qu’est-ce qu’il ouvre à partir des inférences des IA. Comment une IA peut-elle imaginer un hors-champ ? La complétion, au niveau des logiciels, c’est la possibilité automatisée de compléter des données partielles. Ici, la donnée fournie est une photographie, cadrée, il s’agit alors de compléter son hors-champ, de produire son contexte.
Pour la série Complétion, j’ai pris des images historiques. Dont je n’ai pas été le témoin. Dont peut-être plus personne ici, vivant, ne pourra de même témoigner maintenant ou plus tard. Et j’ai utiliser une IA qui fonctionne sans prompt, pour qu’elle imagine à partir de la scène les hors-champs. Le fait que l’IA fonctionne sans aucun prompt est important, car cela met en avant un processus d’imagination artificielle sans vecteur déterminant linguistique de la part de l’utilisateur. L’IA n’a que le contexte photographique. Ici, l’IA fonctionne en deux temps : tout d’abord il y a une perception machine du contexte et une analyse, ensuite, elle produit et complète l’image d’un point de vue génératif. Sans le prompt, elle infère la suite (le hors-champ) de l’image sans autre référence que ce qu’elle en comprend. Complétion ouvre ainsi à une réflexion à une autonomie de l’imaginaire. Alors qu’avec le prompt, on dirige (on induit une vectorialité sémiotique et sémantique dans le modèle), ici on demande seulement à l’IA d’imaginer à partir de sa perception ce que pourrait être le hors champ. Avec Midjourney, ou bien Dall-E 2, l’utilisateur est comme un maître qui donne le sujet que doit réaliser un élève. Complétion propose à une imagination artificielle de générer, sans autre processus que sa propre compréhension non induite, le contexte d’une image.
Boulevard du Temple photographie en daguerréotype réalisée à Paris en 1838 par l’inventeur du procédé, Louis Daguerre. Ce serait la première ou l’une des premières photographie de l’histoire de l’humanité. Et surtout la première photographie où il. aurait un être humain (un cireur de chaussure). La deuxième, est une des photographies de Amstrong sur la lune. Le premier pas de l’homme sur notre satellite. La troisième est celle du Général Degaulle au Québec. La quatrième est celle du jour de l’assassinat de JFK.
1838 – Louis Daguerre réalise la première photographie : Boulevard du Temple. Première captation mécanique, première mémoire technique de l’image. Plus de témoins de ce qui apparaissait hors-champ. La série Complétion se présente comme une complétion du hors-champ par une IA (et ceci sans la détermination du moindre prompt). L’IA, à partir seulement de ce qu’elle peut inférer selon sa perception algorithmique du donné du pixel, vient compléter la photographie, vient constituer ce hors-champ impossible. La photographie générée fait 10000 / 7841 pixels en 300ppp
 Degaulle le 24 – juillet 1967 à Montréal – La photographie est serrée. Le général Degaulle est au premier plan. Dans le paroxysme de son éloquence, il énonce avec force : "Vive le Québec libre". 15000 personnes à le regarder. Les IA génératives sont entrainées avec des sets d’images et des classements linguistiques qui permettent une génération selon une inférence statistique.
Degaulle le 24 – juillet 1967 à Montréal – La photographie est serrée. Le général Degaulle est au premier plan. Dans le paroxysme de son éloquence, il énonce avec force : "Vive le Québec libre". 15000 personnes à le regarder. Les IA génératives sont entrainées avec des sets d’images et des classements linguistiques qui permettent une génération selon une inférence statistique.
En ce sens, l’IA générative ne recherche pas ce qui fait rupture, mais ce qui correspond plus ou moins avec des récurrences, des répétitions, analysées lors des analyses sets d’images. De sorte que les modèles courants qui sont conçus (Midjourney, Dall E 2, Gemini) sont normalisés. S’il y a surprise dans l’image (ou une sorte de réalité qui rompt l’ordinaire) cela provient de l’input de l’utilisateur. Hormis cela, l’IA produit ce qui lui paraît statistiquement le plus probable.
COMPLETION utilise une IA générative sans prompt. Donc l’IA ne se fonde que sur le contexte des données pixels pour déterminer la complétion de l’image. Il n’y a aucune forme d’influence de la part de l’utilisateur. C’est en ce sens que l’IA ne peut envisager d’événement. L’événement pour reprendre Alain Badiou : “ouvre la possibilité qu’une vérité inédite surgisse dans un monde donné”. C’est ce qui vient faire effraction dans l’être (qui est gouverné par Badiou par le mathème, donc l’ordre logis-mathématique). L’événement c’est ce qui fait histoire. Or, si l’IA génère à partir d’une induction statistique, sans autre influence elle va produire du monde selon l’être au sens de Badiou et non pas l’événement.
COMPLETION – 3 – John F. Kennedyen voiture lieu le i 22 novembre 1963 – L’événement historique ici n’aura pas lieu, n’aura pas eu lieu. Car l’espace complété du hors champs n’est pas Dallas. JFK est dans une autre ville, d’un autre temps. La voiture roule, mais personne ne regarde. Le monde est vide. Il n’est pas vidé, car personne n’est jamais venu. Car cette voiture implique un contexte sans histoire, car l’imagination qui imagine ce réel-là, par sa logique inductive, par sa logique statistique, ne peut imaginer ce qui viendrait rompre la chaîne logique d’une ville statistiquement régulière. Seul, un tueur, peut imaginer de rompre la ville régulière et le chemin régulier d’un président qui parade dans une ville.
. //english
 Our memory, sometimes we regret it, is fragmentary. For centuries, there was only retention by consciousness and its memory potential to remember the past in images. That we had experienced, or that we had heard. Photography changed that. While eidetic memory is very rare in humans, with photography, we have been able to make punctures from reality. Looking at a photo is seeing a fragment (temporal and spatial of the past) of what took place. But there is always something off-camera. The off-camera is what has escaped capture and technical memory. We can thus think of photography as a technical prosthesis of our memory. An extension. However, this memory is limited, it is also fragmentary. It is a tiny segment of space and time. A portion.
Our memory, sometimes we regret it, is fragmentary. For centuries, there was only retention by consciousness and its memory potential to remember the past in images. That we had experienced, or that we had heard. Photography changed that. While eidetic memory is very rare in humans, with photography, we have been able to make punctures from reality. Looking at a photo is seeing a fragment (temporal and spatial of the past) of what took place. But there is always something off-camera. The off-camera is what has escaped capture and technical memory. We can thus think of photography as a technical prosthesis of our memory. An extension. However, this memory is limited, it is also fragmentary. It is a tiny segment of space and time. A portion.
With Completion, it seemed necessary to me to question the question of off-camera in the age of AI: if the off-camera of what was memorized is what has disappeared, which I can only imagine, how can it be addressed and what does it open up from AI inferences. How can an AI imagine something off-camera? Completion, at the software level, is the automated possibility of completing partial data. Here, the data provided is a photograph, framed, it is then a question of completing its off-camera, of producing its context.
For the Completion series, I took historical images. Which I did not witness. To which perhaps no one here, alive, will be able to bear witness now or later. And I used an AI that works without prompts, so that it can imagine things off-camera from the scene. The fact that the AI ​​operates without any prompt is important, because it highlights a process of artificial imagination without a linguistic determining vector on the part of the user. The AI ​​only has photographic context. Here, the AI ​​works in two stages: first there is a machine perception of the context and an analysis, then it produces and completes the image from a generative point of view. Without the prompt, it infers the rest (off-camera) of the image without any other reference than what it understands. Completion thus opens up a reflection on the autonomy of the imagination. Whereas with the prompt, we direct (we induce a semiotic and semantic vectorality in the model), here we only ask the AI ​​to imagine from its perception what the off-camera could be. With Midjourney, or Dall-E 2, the user is like a teacher who gives the subject that a student must complete. Completion allows an artificial imagination to generate, without any process other than its own uninduced understanding, the context of an image.
The two photographs proposed in this article: Boulevard du Temple daguerreotype photograph taken in Paris in 1838 by the inventor of the process, Louis Daguerre. It would be the first or one of the first photographs in the history of humanity. The second is one of Amsrong’s photographs on the moon. Man’s first step on our satellite.
1838 – Louis Daguerre made the first photograph: Boulevard du Temple. First mechanical capture, first technical memory of the image. No more witnesses to what appeared off-camera. The Complétion series presents itself as an off-screen completion by an AI (and this without the slightest determination). The AI, based only on what it can infer according to its algorithmic perception of the given pixel, completes the photography, constitutes this impossible off-camera.
Degaulle on July 24, 1967 in Montreal – The photography is tight. General Degaulle is in the foreground. In the paroxysm of his eloquence, he forcefully stated: “Long live free Quebec.” 15,000 people watching it.
Generative AIs are trained with sets of images and linguistic classifications which allow generation according to statistical inference. In this sense, generative AI does not look for what breaks, but what corresponds more or less with recurrences, repetitions, analyzed during image set analyses. So the common models that are designed (Midjourney, Dall E 2, Gemini) are standardized. If there is surprise in the image (or some sort of reality that breaks the ordinary) it comes from user input. Aside from that, the AI ​​produces what appears statistically most likely to it. COMPLETION uses generative AI without prompting. So the AI ​​only relies on the context of the pixel data to determine image completion. There is no form of influence from the user.
It is in this sense that the AI ​​cannot envisage an event. The event, to quote Alain Badiou: “opens the possibility of an unprecedented truth emerging in a given world”. This is what breaks into being (which is governed by Badiou by the matheme, therefore the logis-mathematical order). The event is what makes history. However, if AI generates from statistical induction, without any other influence it will produce the world according to being in the sense of Badiou and not the event.
Degaulle’s photography is tight. We don’t see the 15,000 people. And for the AI, its imagination cannot imagine them. As she cannot imagine what Quebec or freedom is. She only imagines the city according to the highest probability in view of her perception of the image. And Degaulle is alone facing the silence of space.
March 25, 2024 · category article, imagination artificielle, intelligence artificielle
Lorsque l’on regarde la très grande majorité des images issues des IA génératives sans qu’on en prenne conscience notre esprit reconnaît des sources, des origines, en bref a intuitivement accès à un ensemble de données images qui ont été digérées dans le processus de la création du modèle. Les modèles des IA sont construits selon une indexation des images obéissant à notre représentation.
En ce sens l’imaginaire de la machine est construit sur un déterminisme de la perception et de la mémoire humaine. Certes, l’imagination artificielle ne fonctionne pas comme la nôtre, mais du fait du déterminisme catégoriel établi à la fois dans les modèles-images et dans leur correspondance linguistique, l’imaginaire artificiel se conforme à une mémoire que nous avons de nos images.
Olivier Auber a très rapidement décelé ce biais cognitif à travers ses portraits . La génération IA mettait en évidence selon un point aveugle (anoptikon) pour l’utilisateur, la logique d’indexation de nos propres images et de leur logique. C’est en ce sens que les portraits de directeurs de musées, de sociologues (etc) générés se constituent comme des miroirs révélateurs de notre propre logique de mémorisation par l’image. Ce biais cognitif a bien été perçu par les producteurs d’IA, mais il n’est pas facile à rectifier comme nous avons pu le voir avec les nazis ou vikings noirs de Gemini .
.
Ce biais génératif repose sur le fait que l’apprentissage est lié à un découpage du monde selon notre propre logique. Si je veux qu’il y ait des mains, je vais nourrir d’images de mains une IA, et je vais sous-catégoriser ensuite les types de mains (mains ouvertes, fermées, qui tient un objet, etc). La génération de la main ne vient pas de rien, mais d’un apprentissage et de son renforcement. Ainsi, je n’aurai jamais de surprise quand je demanderai de faire une main, ce sera bien une main qui apparaîtra. Certes au tout début des IA génératives, on a pu percevoir à quel point il a été difficile pour les IA de faire des mains, toutefois, comme on le constate avec midjourney ou bien dall-e 2, cette difficulté a été dépassée.
Cependant si au lieu d’utiliser des modèles existant, nous produisons nous même nos modèles que peut-on induire au niveau de la génération ?
Peut-il y avoir encore dans notre perception, celle du regardeur qui n’a pas eu accès à la formation du modèle, une appréhension des images constitutives du modèle ?
C’est le travail que je fais depuis pas mal de mois avec la construction de mes propres modèles. Amener qu’il y ait une forme d’impossibilité archéologique de la mémoire des images. Une suspension de la reconnaissance. Un échec dialectique de l’appropriation ontologique de l’image.
L’appropriation ontologique repose sur la réduction de la machine au simple instrument.
L’imagination artificielle est réduite à être un outil pour l’intentionnalité promptologique de la conscience.
En amenant une IA à produire un modèle, il s’agit de rompre avec la perception humaine, et d’interroger comment l’IA perçoit des possibilités statistiques dans des données hétérogènes.
C’est en ce sens que les images de cette série obéisse à un modèle où j’ai mêlé : à la fois des corps humains, des cordes de bateau nouées, et des ensembles minéraux. Il a été conçu sur environ 10000 images. Et il obéit seulement au prompt body et à un poids.
Le prompt général : « un corps dans une pièce blanche » (a body in a white room)
Aucune prédication de difformité. Aucune volonté de produire de la déformation. Il s’agit de laisser survenir le possible de l’image selon l’imagination artificiel.
Ce qui ressort tient de l’induction statistique et du corps latent suspendu en puissance dans le modèle.
Chaque génération survient alors comme une surprise, car je ne peux apriori anticiper (notamment au début) ce qu’a perçu et comment sera généré la corporéité. Le corps généré n’est ps imparfait, mais il est parfait selon la perception et l’apprentissage de l’IA. Il s’agit strictement d’un pararéalisme de la forme du corps. D’une autre réalité. Pour notre perception, l’archéologie de l’image est suspendue, car intuitivement, nous ne pouvons saisir de quelle manière cela s’est formé.







March 21, 2024 · category article, imagination artificielle, intelligence artificielle, [une]
 En 2018, inaugurant mon travail sur l’imagination artificielle des IA quant à la génération d’image, je me suis mis à travailler sur les possibles d’une faune post-historique. Plus exactement, ma création par l’IA était liée à cette fiction révélante : la conscience d’un être technologique (ET) non humain, tentant après la destruction du monde tel que nous le connaissons d’imaginer ce qu’aurait pu être la faune qui a disparu. Les animaux surgissaient, tous étranges, hybrides de ce que ma mémoire connaissait, mais tous possiblement réels.
En 2018, inaugurant mon travail sur l’imagination artificielle des IA quant à la génération d’image, je me suis mis à travailler sur les possibles d’une faune post-historique. Plus exactement, ma création par l’IA était liée à cette fiction révélante : la conscience d’un être technologique (ET) non humain, tentant après la destruction du monde tel que nous le connaissons d’imaginer ce qu’aurait pu être la faune qui a disparu. Les animaux surgissaient, tous étranges, hybrides de ce que ma mémoire connaissait, mais tous possiblement réels.
Ce qui était assez fascinant entre 2018 et 2021, avant l’arrivée de Dall-e, c’est que les IA que nous pouvions utiliser, tel vqgan, disco-diffusion etc…, toute utilisable sur colab de google, non seulement permettait de saisir un peu leur logique de fonctionnement grâce aux enchainement de scripts python, mais surtout par leurs résultats dévoilaient la différence avec notre imagination humaine. Certes, déjà, ce qui ordonnait énormément de recherche tenait à une mimésis de la perception humaine, toutefois, il était indéniable qu’une forme de psychédélisme, d’hallucination machine avait lieu. La liaison entre le prompt (énoncé donné par un agent humain) et l’image générée par l’agent machine, reposait sur une tension entre dysformation et conformation. Il n’y avait pas en ce temps-là à rechercher des énoncés induisant des difformités dans l’image pour voir surgir des difformités. Toutefois, ce qui apparaissait comme difformité, ou encore erreur, n’était pas lié à un processus d’erreur, mais comme je le notais déjà : à une forme de pararéalisme. C’est pourquoi je rejetais strictement les notions de surréalisme. Le surréalisme, est relié à une forme critique du réalisme comme Ferdinand Alquié l’a parfaitement mis en avant dans La philosophie du surréalisme. Dans cette considération de l’IA domine de fait un primat anthropologique, imposant la réalité perçue humaine comme seule vérité.
Les models des IA, et donc derrière la constitution de l’espace latent à partir d’un deep learning loin de permettre une génération stricte et mimétique permettait d’explorer un imaginaire artificiel et de questionner certaines de nos différences structurelles.
Toutefois, avec l’émergence de dall-e puis dall-e 2, de mid journey, puis de nombreuses IA grand public, ce qui s’est imposé répond de la logique mimétique stricte : la conformité entre le prompt et la génération.
Certes, il peut y avoir une fantaisie de l’image, mais l’image correspond assez précisément à l’énoncé et à ses conditions. L’image au niveau de ses textures, de ses perspectives apparait assez standards. Il est assez facile de reconnaître depuis 2023 une image générée par mid-journey ou bien dall-e.
Pour générer quelque chose qui s’échappe de cette mimétique : l’utilisateur est alors dans l’obligation de rechercher des prompts qui vont artificiellement amener une forme de difformité, de surprise pour le voyeur (Actuellement, Claire Chatelet. Ce n’est pas l’imagination artificielle dans son processus qui crée une difformité, mais l’énoncé (le prompt) qui induit la variation. Dès lors toute aberration de l’image (quand il y en a, mais il y en a peu au niveau de l’image statique contrairement au niveau de l’image animée pour l‘instant) est mimétique et conforme au prompt.
Or ceci conduit à un effacement de la part propre de l’IA. Elle est réduite au simple instrument de production. Mais c’est bien ce qui est demandé. Et en ce sens il était logique que des logiciels, comme photoshop, intègrent nativement une IA de génération. De même qu’il n’st aucunement surprenant qu’on tende à substituer à pas mal d’opérations standards de création l’humain par l’IA.
C’est en ce sens, qu’à partir de 2022, il m’est apparu nécessaire de travailler sur la construction de models propres et de ne plus utiliser systématiquement les models fournis. J’ai commencé sur colab. Puis j’ai poursuivi ce travail avec stable-diffusion en application locale. Construire ses propres models, tout d’abord, c’est admettre que la perception machine fonctionne autrement que notre perception. En effet pour créer un model, il faut entrainer une IA. Notre perception humaine est différenciante, à savoir si je lui donne des images hétérogènes, sans qu’il y ait d’acte conscient (donc au niveau pré-réflexif, au niveau d’une a-perception) il y a différenciation des motifs, une abstraction. Ce qui fait que notre esprit apprend très vite les différences d’objets du monde en produisant des objets intuitifs différents (ce que l’on pourrait nommer ici des concepts). L’IA n’abstrait pas d’une image une représentation, mais son apprentissage se fait par l’analyse de centaines voire de milliers d’images, pour constituer en relation avec un schématisme algorithmique une possibilité statistique d’objet. Or, au cours de mes recherches, il m’est apparu que quelque soit les images qu’on lui donne afin qu’elle crée un model latent : si on lui dit que c’est un corps humain, elle tentera de produire à partir de la diversité des images un corps humain correspondant aux régularités statistiques liées aux images hétérogènes qu’on lui donne.
 En ce sens, en 2022 j’ai commencé à créer des models de décharge. Ces décharges, qui sont des paysages de la catastrophe, au lieu de reposer seulement sur des images de décharge, étaient produites avec des images de chairs, de boucherie, de corps humain et aussi et surtout de décharge. Ce qui me permettait de produire une forme de texture assez unique, et très surprenante. Dans ces générations, il n’y avait en fait aucune forme d’aberration ou de déformation, tout à l’inverse, ces générions étaient conformes à l’apprentissage de l’IA et la constitution de ses models.
En ce sens, en 2022 j’ai commencé à créer des models de décharge. Ces décharges, qui sont des paysages de la catastrophe, au lieu de reposer seulement sur des images de décharge, étaient produites avec des images de chairs, de boucherie, de corps humain et aussi et surtout de décharge. Ce qui me permettait de produire une forme de texture assez unique, et très surprenante. Dans ces générations, il n’y avait en fait aucune forme d’aberration ou de déformation, tout à l’inverse, ces générions étaient conformes à l’apprentissage de l’IA et la constitution de ses models.
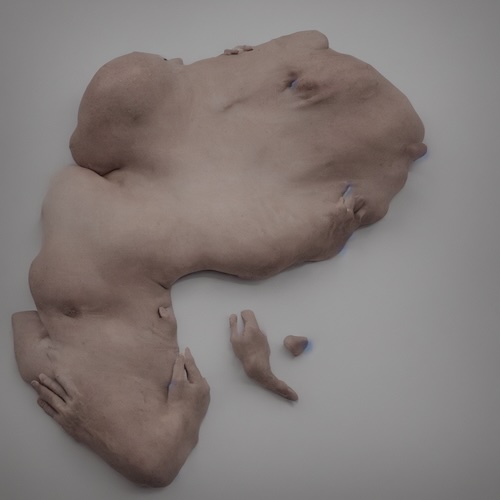 C’est aussi, ce que je développe dans mes séries : L’impossibilité du corps, l’indécision du corps. Les corps qui sont générés ne sont pas des monstres, mais le résultat de models constitués tout autrement que ceux qu’utilisent le grand public. Pour construire ces models, il est nécessaire à mon sens de comprendre tout d’abord la nature de la perception de la machine au cours de son apprentissage et d’autre part la procédure de la génération par diffusion. Dans tous les cas : les corps générés ne sont pas difformes. S’ils le sont ce n’est que pour la perception humaine, qui prend comme norme de jugement ses propres models.
C’est aussi, ce que je développe dans mes séries : L’impossibilité du corps, l’indécision du corps. Les corps qui sont générés ne sont pas des monstres, mais le résultat de models constitués tout autrement que ceux qu’utilisent le grand public. Pour construire ces models, il est nécessaire à mon sens de comprendre tout d’abord la nature de la perception de la machine au cours de son apprentissage et d’autre part la procédure de la génération par diffusion. Dans tous les cas : les corps générés ne sont pas difformes. S’ils le sont ce n’est que pour la perception humaine, qui prend comme norme de jugement ses propres models.
Les corps qui apparaissent sont les possibles d’un espace latent induit par un model spécifique et non mimétique.
February 20, 2024 · category article, imagination artificielle, intelligence artificielle
La nouvelle avancée d’openAI avec Sora a été remarquée, et a rendu une nouvelle fois béat, nombres de commentateurs sur le web, suscitant une avalanche de commentaires, d’articles et de chroniques.
En effet, les videos apparaissent bluffantes au premier abord.
Ce que vise openAI depuis dall-e 2, c’est de combler l’écart entre la projection de la conscience humaine liée au prompt et le rendu par l’imagination artificielle. Plus précisément, de réduire les processus de génération à correspondre aux intuitions de l’espace et du temps qui sont propres à la conscience humaine. Open-AI conçoit les IA, non pas comme l’exploration de possibles, mais selon un réductionnisme mimétique, fondé sur le lien de ressemblance entre le prompt et le rendu, comme si le prompteur (a conscience humaine) déterminait la qualité mimétique du rendu. Il induise alors une forme d’illusion de maîtrise chez l’utilisateur, qui va alors pense qu’il est la cause efficiente du rendu, oubliant la densité de boîte noire algorithmique de l’IA. L’imagination artificielle dans une telle perspective obéit strictement à la logique de représentation de l’esprit humain. J’ai montré cependant à plusieurs reprises, comment ce n’était qu’illusion, notamment dans la série Dreamers.
Avec Sora, openAi s’attaque au temps. Les vidéos de démonstration apparaissent correspondre aux intuitions espace/temps que nous avons, à savoir le temps est celui de la causalité que nous expérimentons en tant que sujet doué de corps. Ainsi, on observe un couple de japonais, marcher au rythme du suivi d’un drone. On suit la course effrénée d’une voiture de rallye, etc… Ce qui bluffe à première vue, c’est la ressemblance de ces images, avec des images que l’on pourrait imaginer de la même situation. Alors que le temps semble être le lieu de la bifurcation entre la conscience humaine et les IA génératives, y compris avec stable video, ou runaway (ce que j’avais analysé déjà dans l’article No time for pictures publié par Vidéoformes), openAI, semblerait avoir résolu cet écart.
 Toutefois le schématisme temporel des imaginations artificielles n’est pas du tout du même ordre que celui qui se constitue dans notre conscience.
Toutefois le schématisme temporel des imaginations artificielles n’est pas du tout du même ordre que celui qui se constitue dans notre conscience.
Une vidéo produite par Sora montre parfaitement cela. Elle a été abondamment partagée : quatre hommes déterrent deux chaises en plastique. Le contexte et les hommes apparaissent très bien reproduits, de même que leur démarche. Toutefois, lorsqu’ils se saisissent de la chaise, étrangement celle-ci s’anime seule, suspendue dans le vide, avançant sans causalité motrice.
La nature du temps et de la causalité propre à l’imagination artificielle se dévoile. Le temps n’est pas lié à des lois physiques qui gouverneraient un univers, mais la liaison causale est liée à une induction issue de l’analyse statistique de vidéos et de suites d’images. Or une suite d’images ne fait pas le temps. Intuition bergsonienne du temps par rapport au cinéma, que l’on pourrait actualiser vis-à-vis de l’interpolation du mouvement et des interactions dans la temporalité des imaginations artificielles.
L’imagination artificielle, et c’est cela qui est intéressant, n’imagine pas un monde soumis à des causalités de corps. Car Les IA n’ont pas expérimentés un monde par un corps, mais les IA imaginent un monde à partir des images que nous produisons du monde. Jean-Noël Lafargue a raison d’écrire : « Les images produites par Sora n’ont pas pour référence notre perception du réel, elles se réfèrent à des images déjà produites » (Voir et penser comme des machines) Ainsi, les formes apriori du temps de l’imagination artificielles sont à penser à partir de la question de l’interpolation des images. Alors que les formes apriori du temps de l’intuition sensible humaine, se sont constituées au cours de millénaire d’expérience d’un monde et de sa donation.
Il ne s’agit pas de penser une autonomie des IA dans ce processus, mais de saisir en quelque sorte une transcendantalité de l’imagination artificielle générative, qui serait différente de celle des hommes. Sans cette reconnaissance, la conscience humaine ne peut que vouloir résoudre la différence, afin de s’assurer de la maîtrise purement instrumentale de l’IA, et de là occulter et nier toute expérience de et avec cette imagination artificielle.
Par la reconnaissance d’une transcendantalité des IA, qui ne supposent aucunement la consistance d’un noyau de conscience (Simondon) mais plutôt une nature réticulaire, la conscience humaine peut alors explorer en inter-relation avec les possibles ouverts par les IA, de nouvelles configurations de possibles (ce que j’ai nommés un pararéalisme), qui apriori lui étaient étrangers.
Next entries »