March 25, 2024 · category article, imagination artificielle, intelligence artificielle
Lorsque l’on regarde la très grande majorité des images issues des IA génératives sans qu’on en prenne conscience notre esprit reconnaît des sources, des origines, en bref a intuitivement accès à un ensemble de données images qui ont été digérées dans le processus de la création du modèle. Les modèles des IA sont construits selon une indexation des images obéissant à notre représentation.
En ce sens l’imaginaire de la machine est construit sur un déterminisme de la perception et de la mémoire humaine. Certes, l’imagination artificielle ne fonctionne pas comme la nôtre, mais du fait du déterminisme catégoriel établi à la fois dans les modèles-images et dans leur correspondance linguistique, l’imaginaire artificiel se conforme à une mémoire que nous avons de nos images.
Olivier Auber a très rapidement décelé ce biais cognitif à travers ses portraits . La génération IA mettait en évidence selon un point aveugle (anoptikon) pour l’utilisateur, la logique d’indexation de nos propres images et de leur logique. C’est en ce sens que les portraits de directeurs de musées, de sociologues (etc) générés se constituent comme des miroirs révélateurs de notre propre logique de mémorisation par l’image. Ce biais cognitif a bien été perçu par les producteurs d’IA, mais il n’est pas facile à rectifier comme nous avons pu le voir avec les nazis ou vikings noirs de Gemini .
.
Ce biais génératif repose sur le fait que l’apprentissage est lié à un découpage du monde selon notre propre logique. Si je veux qu’il y ait des mains, je vais nourrir d’images de mains une IA, et je vais sous-catégoriser ensuite les types de mains (mains ouvertes, fermées, qui tient un objet, etc). La génération de la main ne vient pas de rien, mais d’un apprentissage et de son renforcement. Ainsi, je n’aurai jamais de surprise quand je demanderai de faire une main, ce sera bien une main qui apparaîtra. Certes au tout début des IA génératives, on a pu percevoir à quel point il a été difficile pour les IA de faire des mains, toutefois, comme on le constate avec midjourney ou bien dall-e 2, cette difficulté a été dépassée.
Cependant si au lieu d’utiliser des modèles existant, nous produisons nous même nos modèles que peut-on induire au niveau de la génération ?
Peut-il y avoir encore dans notre perception, celle du regardeur qui n’a pas eu accès à la formation du modèle, une appréhension des images constitutives du modèle ?
C’est le travail que je fais depuis pas mal de mois avec la construction de mes propres modèles. Amener qu’il y ait une forme d’impossibilité archéologique de la mémoire des images. Une suspension de la reconnaissance. Un échec dialectique de l’appropriation ontologique de l’image.
L’appropriation ontologique repose sur la réduction de la machine au simple instrument.
L’imagination artificielle est réduite à être un outil pour l’intentionnalité promptologique de la conscience.
En amenant une IA à produire un modèle, il s’agit de rompre avec la perception humaine, et d’interroger comment l’IA perçoit des possibilités statistiques dans des données hétérogènes.
C’est en ce sens que les images de cette série obéisse à un modèle où j’ai mêlé : à la fois des corps humains, des cordes de bateau nouées, et des ensembles minéraux. Il a été conçu sur environ 10000 images. Et il obéit seulement au prompt body et à un poids.
Le prompt général : « un corps dans une pièce blanche » (a body in a white room)
Aucune prédication de difformité. Aucune volonté de produire de la déformation. Il s’agit de laisser survenir le possible de l’image selon l’imagination artificiel.
Ce qui ressort tient de l’induction statistique et du corps latent suspendu en puissance dans le modèle.
Chaque génération survient alors comme une surprise, car je ne peux apriori anticiper (notamment au début) ce qu’a perçu et comment sera généré la corporéité. Le corps généré n’est ps imparfait, mais il est parfait selon la perception et l’apprentissage de l’IA. Il s’agit strictement d’un pararéalisme de la forme du corps. D’une autre réalité. Pour notre perception, l’archéologie de l’image est suspendue, car intuitivement, nous ne pouvons saisir de quelle manière cela s’est formé.







March 21, 2024 · category article, imagination artificielle, intelligence artificielle, [une]
 En 2018, inaugurant mon travail sur l’imagination artificielle des IA quant à la génération d’image, je me suis mis à travailler sur les possibles d’une faune post-historique. Plus exactement, ma création par l’IA était liée à cette fiction révélante : la conscience d’un être technologique (ET) non humain, tentant après la destruction du monde tel que nous le connaissons d’imaginer ce qu’aurait pu être la faune qui a disparu. Les animaux surgissaient, tous étranges, hybrides de ce que ma mémoire connaissait, mais tous possiblement réels.
En 2018, inaugurant mon travail sur l’imagination artificielle des IA quant à la génération d’image, je me suis mis à travailler sur les possibles d’une faune post-historique. Plus exactement, ma création par l’IA était liée à cette fiction révélante : la conscience d’un être technologique (ET) non humain, tentant après la destruction du monde tel que nous le connaissons d’imaginer ce qu’aurait pu être la faune qui a disparu. Les animaux surgissaient, tous étranges, hybrides de ce que ma mémoire connaissait, mais tous possiblement réels.
Ce qui était assez fascinant entre 2018 et 2021, avant l’arrivée de Dall-e, c’est que les IA que nous pouvions utiliser, tel vqgan, disco-diffusion etc…, toute utilisable sur colab de google, non seulement permettait de saisir un peu leur logique de fonctionnement grâce aux enchainement de scripts python, mais surtout par leurs résultats dévoilaient la différence avec notre imagination humaine. Certes, déjà, ce qui ordonnait énormément de recherche tenait à une mimésis de la perception humaine, toutefois, il était indéniable qu’une forme de psychédélisme, d’hallucination machine avait lieu. La liaison entre le prompt (énoncé donné par un agent humain) et l’image générée par l’agent machine, reposait sur une tension entre dysformation et conformation. Il n’y avait pas en ce temps-là à rechercher des énoncés induisant des difformités dans l’image pour voir surgir des difformités. Toutefois, ce qui apparaissait comme difformité, ou encore erreur, n’était pas lié à un processus d’erreur, mais comme je le notais déjà : à une forme de pararéalisme. C’est pourquoi je rejetais strictement les notions de surréalisme. Le surréalisme, est relié à une forme critique du réalisme comme Ferdinand Alquié l’a parfaitement mis en avant dans La philosophie du surréalisme. Dans cette considération de l’IA domine de fait un primat anthropologique, imposant la réalité perçue humaine comme seule vérité.
Les models des IA, et donc derrière la constitution de l’espace latent à partir d’un deep learning loin de permettre une génération stricte et mimétique permettait d’explorer un imaginaire artificiel et de questionner certaines de nos différences structurelles.
Toutefois, avec l’émergence de dall-e puis dall-e 2, de mid journey, puis de nombreuses IA grand public, ce qui s’est imposé répond de la logique mimétique stricte : la conformité entre le prompt et la génération.
Certes, il peut y avoir une fantaisie de l’image, mais l’image correspond assez précisément à l’énoncé et à ses conditions. L’image au niveau de ses textures, de ses perspectives apparait assez standards. Il est assez facile de reconnaître depuis 2023 une image générée par mid-journey ou bien dall-e.
Pour générer quelque chose qui s’échappe de cette mimétique : l’utilisateur est alors dans l’obligation de rechercher des prompts qui vont artificiellement amener une forme de difformité, de surprise pour le voyeur (Actuellement, Claire Chatelet. Ce n’est pas l’imagination artificielle dans son processus qui crée une difformité, mais l’énoncé (le prompt) qui induit la variation. Dès lors toute aberration de l’image (quand il y en a, mais il y en a peu au niveau de l’image statique contrairement au niveau de l’image animée pour l‘instant) est mimétique et conforme au prompt.
Or ceci conduit à un effacement de la part propre de l’IA. Elle est réduite au simple instrument de production. Mais c’est bien ce qui est demandé. Et en ce sens il était logique que des logiciels, comme photoshop, intègrent nativement une IA de génération. De même qu’il n’st aucunement surprenant qu’on tende à substituer à pas mal d’opérations standards de création l’humain par l’IA.
C’est en ce sens, qu’à partir de 2022, il m’est apparu nécessaire de travailler sur la construction de models propres et de ne plus utiliser systématiquement les models fournis. J’ai commencé sur colab. Puis j’ai poursuivi ce travail avec stable-diffusion en application locale. Construire ses propres models, tout d’abord, c’est admettre que la perception machine fonctionne autrement que notre perception. En effet pour créer un model, il faut entrainer une IA. Notre perception humaine est différenciante, à savoir si je lui donne des images hétérogènes, sans qu’il y ait d’acte conscient (donc au niveau pré-réflexif, au niveau d’une a-perception) il y a différenciation des motifs, une abstraction. Ce qui fait que notre esprit apprend très vite les différences d’objets du monde en produisant des objets intuitifs différents (ce que l’on pourrait nommer ici des concepts). L’IA n’abstrait pas d’une image une représentation, mais son apprentissage se fait par l’analyse de centaines voire de milliers d’images, pour constituer en relation avec un schématisme algorithmique une possibilité statistique d’objet. Or, au cours de mes recherches, il m’est apparu que quelque soit les images qu’on lui donne afin qu’elle crée un model latent : si on lui dit que c’est un corps humain, elle tentera de produire à partir de la diversité des images un corps humain correspondant aux régularités statistiques liées aux images hétérogènes qu’on lui donne.
 En ce sens, en 2022 j’ai commencé à créer des models de décharge. Ces décharges, qui sont des paysages de la catastrophe, au lieu de reposer seulement sur des images de décharge, étaient produites avec des images de chairs, de boucherie, de corps humain et aussi et surtout de décharge. Ce qui me permettait de produire une forme de texture assez unique, et très surprenante. Dans ces générations, il n’y avait en fait aucune forme d’aberration ou de déformation, tout à l’inverse, ces générions étaient conformes à l’apprentissage de l’IA et la constitution de ses models.
En ce sens, en 2022 j’ai commencé à créer des models de décharge. Ces décharges, qui sont des paysages de la catastrophe, au lieu de reposer seulement sur des images de décharge, étaient produites avec des images de chairs, de boucherie, de corps humain et aussi et surtout de décharge. Ce qui me permettait de produire une forme de texture assez unique, et très surprenante. Dans ces générations, il n’y avait en fait aucune forme d’aberration ou de déformation, tout à l’inverse, ces générions étaient conformes à l’apprentissage de l’IA et la constitution de ses models.
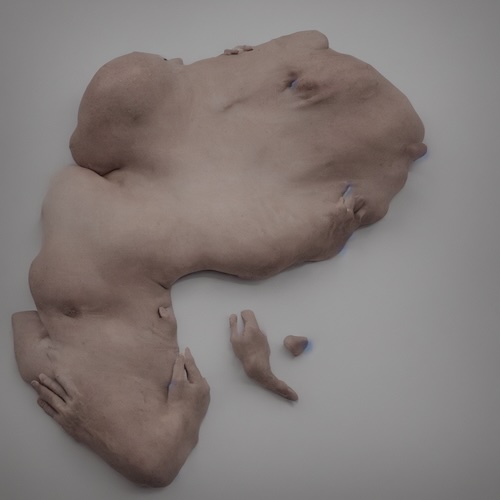 C’est aussi, ce que je développe dans mes séries : L’impossibilité du corps, l’indécision du corps. Les corps qui sont générés ne sont pas des monstres, mais le résultat de models constitués tout autrement que ceux qu’utilisent le grand public. Pour construire ces models, il est nécessaire à mon sens de comprendre tout d’abord la nature de la perception de la machine au cours de son apprentissage et d’autre part la procédure de la génération par diffusion. Dans tous les cas : les corps générés ne sont pas difformes. S’ils le sont ce n’est que pour la perception humaine, qui prend comme norme de jugement ses propres models.
C’est aussi, ce que je développe dans mes séries : L’impossibilité du corps, l’indécision du corps. Les corps qui sont générés ne sont pas des monstres, mais le résultat de models constitués tout autrement que ceux qu’utilisent le grand public. Pour construire ces models, il est nécessaire à mon sens de comprendre tout d’abord la nature de la perception de la machine au cours de son apprentissage et d’autre part la procédure de la génération par diffusion. Dans tous les cas : les corps générés ne sont pas difformes. S’ils le sont ce n’est que pour la perception humaine, qui prend comme norme de jugement ses propres models.
Les corps qui apparaissent sont les possibles d’un espace latent induit par un model spécifique et non mimétique.