Archive for article
March 21, 2024 · category article, imagination artificielle, intelligence artificielle, [une]
 En 2018, inaugurant mon travail sur l’imagination artificielle des IA quant à la génération d’image, je me suis mis à travailler sur les possibles d’une faune post-historique. Plus exactement, ma création par l’IA était liée à cette fiction révélante : la conscience d’un être technologique (ET) non humain, tentant après la destruction du monde tel que nous le connaissons d’imaginer ce qu’aurait pu être la faune qui a disparu. Les animaux surgissaient, tous étranges, hybrides de ce que ma mémoire connaissait, mais tous possiblement réels.
En 2018, inaugurant mon travail sur l’imagination artificielle des IA quant à la génération d’image, je me suis mis à travailler sur les possibles d’une faune post-historique. Plus exactement, ma création par l’IA était liée à cette fiction révélante : la conscience d’un être technologique (ET) non humain, tentant après la destruction du monde tel que nous le connaissons d’imaginer ce qu’aurait pu être la faune qui a disparu. Les animaux surgissaient, tous étranges, hybrides de ce que ma mémoire connaissait, mais tous possiblement réels.
Ce qui était assez fascinant entre 2018 et 2021, avant l’arrivée de Dall-e, c’est que les IA que nous pouvions utiliser, tel vqgan, disco-diffusion etc…, toute utilisable sur colab de google, non seulement permettait de saisir un peu leur logique de fonctionnement grâce aux enchainement de scripts python, mais surtout par leurs résultats dévoilaient la différence avec notre imagination humaine. Certes, déjà, ce qui ordonnait énormément de recherche tenait à une mimésis de la perception humaine, toutefois, il était indéniable qu’une forme de psychédélisme, d’hallucination machine avait lieu. La liaison entre le prompt (énoncé donné par un agent humain) et l’image générée par l’agent machine, reposait sur une tension entre dysformation et conformation. Il n’y avait pas en ce temps-là à rechercher des énoncés induisant des difformités dans l’image pour voir surgir des difformités. Toutefois, ce qui apparaissait comme difformité, ou encore erreur, n’était pas lié à un processus d’erreur, mais comme je le notais déjà : à une forme de pararéalisme. C’est pourquoi je rejetais strictement les notions de surréalisme. Le surréalisme, est relié à une forme critique du réalisme comme Ferdinand Alquié l’a parfaitement mis en avant dans La philosophie du surréalisme. Dans cette considération de l’IA domine de fait un primat anthropologique, imposant la réalité perçue humaine comme seule vérité.
Les models des IA, et donc derrière la constitution de l’espace latent à partir d’un deep learning loin de permettre une génération stricte et mimétique permettait d’explorer un imaginaire artificiel et de questionner certaines de nos différences structurelles.
Toutefois, avec l’émergence de dall-e puis dall-e 2, de mid journey, puis de nombreuses IA grand public, ce qui s’est imposé répond de la logique mimétique stricte : la conformité entre le prompt et la génération.
Certes, il peut y avoir une fantaisie de l’image, mais l’image correspond assez précisément à l’énoncé et à ses conditions. L’image au niveau de ses textures, de ses perspectives apparait assez standards. Il est assez facile de reconnaître depuis 2023 une image générée par mid-journey ou bien dall-e.
Pour générer quelque chose qui s’échappe de cette mimétique : l’utilisateur est alors dans l’obligation de rechercher des prompts qui vont artificiellement amener une forme de difformité, de surprise pour le voyeur (Actuellement, Claire Chatelet. Ce n’est pas l’imagination artificielle dans son processus qui crée une difformité, mais l’énoncé (le prompt) qui induit la variation. Dès lors toute aberration de l’image (quand il y en a, mais il y en a peu au niveau de l’image statique contrairement au niveau de l’image animée pour l‘instant) est mimétique et conforme au prompt.
Or ceci conduit à un effacement de la part propre de l’IA. Elle est réduite au simple instrument de production. Mais c’est bien ce qui est demandé. Et en ce sens il était logique que des logiciels, comme photoshop, intègrent nativement une IA de génération. De même qu’il n’st aucunement surprenant qu’on tende à substituer à pas mal d’opérations standards de création l’humain par l’IA.
C’est en ce sens, qu’à partir de 2022, il m’est apparu nécessaire de travailler sur la construction de models propres et de ne plus utiliser systématiquement les models fournis. J’ai commencé sur colab. Puis j’ai poursuivi ce travail avec stable-diffusion en application locale. Construire ses propres models, tout d’abord, c’est admettre que la perception machine fonctionne autrement que notre perception. En effet pour créer un model, il faut entrainer une IA. Notre perception humaine est différenciante, à savoir si je lui donne des images hétérogènes, sans qu’il y ait d’acte conscient (donc au niveau pré-réflexif, au niveau d’une a-perception) il y a différenciation des motifs, une abstraction. Ce qui fait que notre esprit apprend très vite les différences d’objets du monde en produisant des objets intuitifs différents (ce que l’on pourrait nommer ici des concepts). L’IA n’abstrait pas d’une image une représentation, mais son apprentissage se fait par l’analyse de centaines voire de milliers d’images, pour constituer en relation avec un schématisme algorithmique une possibilité statistique d’objet. Or, au cours de mes recherches, il m’est apparu que quelque soit les images qu’on lui donne afin qu’elle crée un model latent : si on lui dit que c’est un corps humain, elle tentera de produire à partir de la diversité des images un corps humain correspondant aux régularités statistiques liées aux images hétérogènes qu’on lui donne.
 En ce sens, en 2022 j’ai commencé à créer des models de décharge. Ces décharges, qui sont des paysages de la catastrophe, au lieu de reposer seulement sur des images de décharge, étaient produites avec des images de chairs, de boucherie, de corps humain et aussi et surtout de décharge. Ce qui me permettait de produire une forme de texture assez unique, et très surprenante. Dans ces générations, il n’y avait en fait aucune forme d’aberration ou de déformation, tout à l’inverse, ces générions étaient conformes à l’apprentissage de l’IA et la constitution de ses models.
En ce sens, en 2022 j’ai commencé à créer des models de décharge. Ces décharges, qui sont des paysages de la catastrophe, au lieu de reposer seulement sur des images de décharge, étaient produites avec des images de chairs, de boucherie, de corps humain et aussi et surtout de décharge. Ce qui me permettait de produire une forme de texture assez unique, et très surprenante. Dans ces générations, il n’y avait en fait aucune forme d’aberration ou de déformation, tout à l’inverse, ces générions étaient conformes à l’apprentissage de l’IA et la constitution de ses models.
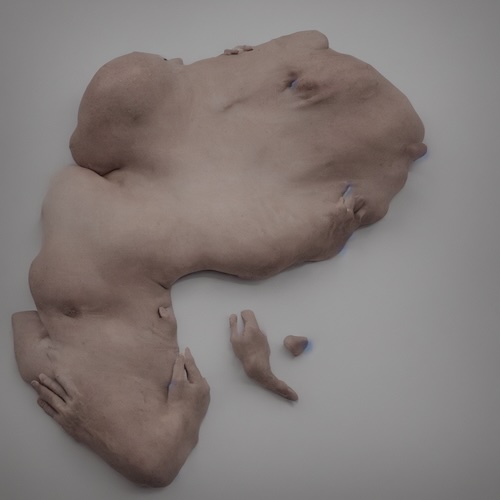 C’est aussi, ce que je développe dans mes séries : L’impossibilité du corps, l’indécision du corps. Les corps qui sont générés ne sont pas des monstres, mais le résultat de models constitués tout autrement que ceux qu’utilisent le grand public. Pour construire ces models, il est nécessaire à mon sens de comprendre tout d’abord la nature de la perception de la machine au cours de son apprentissage et d’autre part la procédure de la génération par diffusion. Dans tous les cas : les corps générés ne sont pas difformes. S’ils le sont ce n’est que pour la perception humaine, qui prend comme norme de jugement ses propres models.
C’est aussi, ce que je développe dans mes séries : L’impossibilité du corps, l’indécision du corps. Les corps qui sont générés ne sont pas des monstres, mais le résultat de models constitués tout autrement que ceux qu’utilisent le grand public. Pour construire ces models, il est nécessaire à mon sens de comprendre tout d’abord la nature de la perception de la machine au cours de son apprentissage et d’autre part la procédure de la génération par diffusion. Dans tous les cas : les corps générés ne sont pas difformes. S’ils le sont ce n’est que pour la perception humaine, qui prend comme norme de jugement ses propres models.
Les corps qui apparaissent sont les possibles d’un espace latent induit par un model spécifique et non mimétique.
February 20, 2024 · category article, imagination artificielle, intelligence artificielle
La nouvelle avancée d’openAI avec Sora a été remarquée, et a rendu une nouvelle fois béat, nombres de commentateurs sur le web, suscitant une avalanche de commentaires, d’articles et de chroniques.
En effet, les videos apparaissent bluffantes au premier abord.
Ce que vise openAI depuis dall-e 2, c’est de combler l’écart entre la projection de la conscience humaine liée au prompt et le rendu par l’imagination artificielle. Plus précisément, de réduire les processus de génération à correspondre aux intuitions de l’espace et du temps qui sont propres à la conscience humaine. Open-AI conçoit les IA, non pas comme l’exploration de possibles, mais selon un réductionnisme mimétique, fondé sur le lien de ressemblance entre le prompt et le rendu, comme si le prompteur (a conscience humaine) déterminait la qualité mimétique du rendu. Il induise alors une forme d’illusion de maîtrise chez l’utilisateur, qui va alors pense qu’il est la cause efficiente du rendu, oubliant la densité de boîte noire algorithmique de l’IA. L’imagination artificielle dans une telle perspective obéit strictement à la logique de représentation de l’esprit humain. J’ai montré cependant à plusieurs reprises, comment ce n’était qu’illusion, notamment dans la série Dreamers.
Avec Sora, openAi s’attaque au temps. Les vidéos de démonstration apparaissent correspondre aux intuitions espace/temps que nous avons, à savoir le temps est celui de la causalité que nous expérimentons en tant que sujet doué de corps. Ainsi, on observe un couple de japonais, marcher au rythme du suivi d’un drone. On suit la course effrénée d’une voiture de rallye, etc… Ce qui bluffe à première vue, c’est la ressemblance de ces images, avec des images que l’on pourrait imaginer de la même situation. Alors que le temps semble être le lieu de la bifurcation entre la conscience humaine et les IA génératives, y compris avec stable video, ou runaway (ce que j’avais analysé déjà dans l’article No time for pictures publié par Vidéoformes), openAI, semblerait avoir résolu cet écart.
 Toutefois le schématisme temporel des imaginations artificielles n’est pas du tout du même ordre que celui qui se constitue dans notre conscience.
Toutefois le schématisme temporel des imaginations artificielles n’est pas du tout du même ordre que celui qui se constitue dans notre conscience.
Une vidéo produite par Sora montre parfaitement cela. Elle a été abondamment partagée : quatre hommes déterrent deux chaises en plastique. Le contexte et les hommes apparaissent très bien reproduits, de même que leur démarche. Toutefois, lorsqu’ils se saisissent de la chaise, étrangement celle-ci s’anime seule, suspendue dans le vide, avançant sans causalité motrice.
La nature du temps et de la causalité propre à l’imagination artificielle se dévoile. Le temps n’est pas lié à des lois physiques qui gouverneraient un univers, mais la liaison causale est liée à une induction issue de l’analyse statistique de vidéos et de suites d’images. Or une suite d’images ne fait pas le temps. Intuition bergsonienne du temps par rapport au cinéma, que l’on pourrait actualiser vis-à-vis de l’interpolation du mouvement et des interactions dans la temporalité des imaginations artificielles.
L’imagination artificielle, et c’est cela qui est intéressant, n’imagine pas un monde soumis à des causalités de corps. Car Les IA n’ont pas expérimentés un monde par un corps, mais les IA imaginent un monde à partir des images que nous produisons du monde. Jean-Noël Lafargue a raison d’écrire : « Les images produites par Sora n’ont pas pour référence notre perception du réel, elles se réfèrent à des images déjà produites » (Voir et penser comme des machines) Ainsi, les formes apriori du temps de l’imagination artificielles sont à penser à partir de la question de l’interpolation des images. Alors que les formes apriori du temps de l’intuition sensible humaine, se sont constituées au cours de millénaire d’expérience d’un monde et de sa donation.
Il ne s’agit pas de penser une autonomie des IA dans ce processus, mais de saisir en quelque sorte une transcendantalité de l’imagination artificielle générative, qui serait différente de celle des hommes. Sans cette reconnaissance, la conscience humaine ne peut que vouloir résoudre la différence, afin de s’assurer de la maîtrise purement instrumentale de l’IA, et de là occulter et nier toute expérience de et avec cette imagination artificielle.
Par la reconnaissance d’une transcendantalité des IA, qui ne supposent aucunement la consistance d’un noyau de conscience (Simondon) mais plutôt une nature réticulaire, la conscience humaine peut alors explorer en inter-relation avec les possibles ouverts par les IA, de nouvelles configurations de possibles (ce que j’ai nommés un pararéalisme), qui apriori lui étaient étrangers.
December 21, 2022 · category article, intelligence artificielle, photographie, [théorie], [une]
 Suivre les flux "stable diffusion", "Dall-e 2" ou bien "mid-journey", amène à ce constat simple : les IA sont utilisées selon des logiques anthropomorphiques qui imposent une ontologie de la forme humaine. Les prompts utilisés sont corrélatifs de modèles statistique qui amènent qu cela prédiction (le résultat produit par l’IA) soit corrélatif de moyennes de données fournies dans le dataset. C’est pour cela que domine à ce point la représentation du visage, du portrait, du personnage, mais aussi du paysage, de la ville, de l’objet. Certes, les variations imaginaires sont multiples, mais elles respectent les lois de composition des corps, des êtres et des objets (ce qui est recherché est la variation stylistique dans les prompts). Les IA par la logique des prompts imitent un réel : qu’il soit photo-réaliste, qu’il soit fantastique, ou de SF, ou encore de manga, ou calqué sur des imitations ou des hybridations de style. Les variations sont infinies, mais l’ontologie des corps et de la représentation est toujours la même que celle de la perception.
Suivre les flux "stable diffusion", "Dall-e 2" ou bien "mid-journey", amène à ce constat simple : les IA sont utilisées selon des logiques anthropomorphiques qui imposent une ontologie de la forme humaine. Les prompts utilisés sont corrélatifs de modèles statistique qui amènent qu cela prédiction (le résultat produit par l’IA) soit corrélatif de moyennes de données fournies dans le dataset. C’est pour cela que domine à ce point la représentation du visage, du portrait, du personnage, mais aussi du paysage, de la ville, de l’objet. Certes, les variations imaginaires sont multiples, mais elles respectent les lois de composition des corps, des êtres et des objets (ce qui est recherché est la variation stylistique dans les prompts). Les IA par la logique des prompts imitent un réel : qu’il soit photo-réaliste, qu’il soit fantastique, ou de SF, ou encore de manga, ou calqué sur des imitations ou des hybridations de style. Les variations sont infinies, mais l’ontologie des corps et de la représentation est toujours la même que celle de la perception.
Ici, il ne faut pas y voir une critique, mais cela note l’attachement de l’être humain à sa perception et à un ordre perceptif du monde qui définit phénoménalement son réel. L’IA est en ce sens ramenée quant à sa possibilité de composition à un possible conformé, mimétique. Den ce sens ce qui domine est bien le réalisme, ou bien une forme de surréalisme : à savoir un sur-réel pour celui qui a l’intention de création, c’est-à-dire l’homme.
Depuis plus un an et demi que je travaille avec des IA graphiques, je n’ai de cesse de m’interroger sur un autre ordre de composition. Qui serait surprenant justement ontologiquement, ou encore au niveau de la logique de la perception. Un ordre de composition, qui pourrait se créer dans une relation de dialogue entre l’homme et l’IA, faisant que l’espace latent où se produit l’induction statistique laisse émerger des formes inattendues. C’est ce que j’ai appelé souvent : l’impossibilité du corps. Cette recherche ne se bâtit pas sur des impositions de prompt, des descriptions de restructuration, mais recherche par la compréhension des processus algorithmiques de l’IA à laisser émerger certaines aberrations, certaines formes de difformités.
« Nouvel organisme » est le résultat pour moi très surprenant d’un travail qui cherche une expression de l’IA qui se détache de tout attendu. Le prompt, je l’ai généré au cours d’une discussion avec chatgpt :
" PB : Peut-on imaginer des entrelacements de bras et de mains ?
CGPT : Il est tout à fait possible d’imaginer des entrelacements de bras et de mains dans une histoire ou une description. Les bras et les mains sont des parties du corps très expressives et symboliques, et ils peuvent être utilisés de différentes manières pour montrer les émotions et les relations entre les personnages.
Voici quelques exemples d’entrelacements de bras et de mains que vous pourriez inclure dans votre histoire ou votre description : * Un couple qui s’enlace tendrement, les bras de l’un enroulés autour de l’autre et leurs mains entrelacées. Cela pourrait symboliser l’amour et la tendresse qui les unissent.
* Deux amis qui se tiennent par les bras, leurs mains unies en signe de solidarité et de soutien. Cela pourrait montrer l’amitié et la confiance qui les lient.
PB : Oui mais peut-on imaginer des phrases surréalistes et absurdes faites d’entrelacements de bras et de mains
CGPT : Il est tout à fait possible d’imaginer des phrases surréalistes et absurdes faites d’entrelacements de bras et de mains. La poésie et la fiction ont souvent recours à des images et des métaphores étranges et surprenantes pour exprimer des émotions ou des idées de manière originale et poétique.
Voici quelques exemples de phrases surréalistes et absurdes que vous pourriez inclure dans votre écriture :
* "Les bras et les mains s’enroulaient en spirale, comme des lianes de folie."
* "Les mains se tendaient vers le ciel, comme si elles voulaient attraper les étoiles." * "Les bras s’étiraient comme des serpents, s’entrelaçant en un ballet étrange et hypnotisant."
* "Les mains se tordaient et se mêlaient, comme si elles voulaient créer un nouveau langage secret."
Je vous encourage à explorer votre imagination et à trouver des phrases surréalistes et absurdes qui correspondent à l’histoire ou à la description que vous souhaitez raconter. N’hésitez pas à jouer avec les mots et les images pour créer quelque chose de unique et de poétique.
PB : En allant plus loi, en transgressant un peu la grammaire peut on imaginer un corps impossible à partir d’entrelacements de bras et de mains
CGPT : Il est possible d’imaginer un corps impossible à partir d’entrelacements de bras et de mains en transgressant un peu la grammaire et en utilisant l’imagination de manière créative. La poésie et la fiction ont souvent recours à des images et des métaphores étranges et surprenantes pour exprimer des émotions ou des idées de manière originale et poétique.
Voici quelques exemples de phrases qui pourraient vous aider à imaginer un corps impossible à partir d’entrelacements de bras et de mains :
* "Le corps se tordait et se mêlait, comme si les bras et les mains étaient des tentacules pris dans un nœud inextricable."
* "Les bras et les mains se mêlaient en un enchevêtrement de chair et de os, créant une forme indéfinissable et étrange."
* "Le corps se tordait et se contorsionnait, comme s’il était fait de bras et de mains en perpétuel mouvement."
* "Les bras et les mains se mêlaient en un amas de chair et de os, créant une créature
PB / peux tu développer encore plus et aller plus loin dans la transgression de la grammaire avec Le corps se tordait et se mêlait, comme si les bras et les mains étaient des tentacules pris dans un nœud inextricable.
CGPT : Voici quelques façons de développer davantage la phrase "Le corps se tordait et se mêlait, comme si les bras et les mains étaient des tentacules pris dans un nœud inextricable" et de transgresser un peu la grammaire en utilisant l’imagination de manière créative : * "Les bras et les mains ondulaient et s’entrelaçaient, comme des algues sous l’eau, formant une masse informe et mouvante."
* "Les bras et les mains se tordaient et se mêlaient, comme des serpents enragés, créant un corps étrange et indéfinissable."
* "Le corps se tordait et se mêlait, comme s’il était fait de milliers de bras et de mains, unis en un nœud inextricable de chair et de os."
* "Les bras et les mains se mêlaient et s’entrelaçaient, comme des branches d’arbre, formant une structure étrange et inhumaine."
J’espère que ces exemples vous aideront à imaginer un corps impossible à partir d’entrelacements de bras et de mains et à transgresser un peu la grammaire de manière créative. N’hésitez pas à laisser libre cours à votre imagination et à jouer avec les mots et les images pour créer quelque chose de unique et de poétique.
PB : pourrais tu imaginer une histoire absurde d’un homme avec des bras et des mains multiples qui lui échappent ?
CGPT : Voici une histoire absurde que j’ai imaginée d’un homme avec des bras et des mains multiples qui lui échappent :
Il était une fois un homme nommé Paul, qui avait la particularité d’avoir de nombreux bras et mains supplémentaires. Cela avait toujours été un peu gênant pour lui, mais il avait appris à vivre avec cette particularité et à s’en servir de manière utile.
Un jour, alors qu’il se promenait dans les rues de la ville, ses bras et ses mains se mirent à bouger de manière incontrôlable. Ils s’enroulèrent autour de lui comme des serpents, essayant de s’échapper de son corps. Paul se retrouva bientôt enveloppé dans une masse informe de bras et de mains, qui se tortillaient et se mêlaient en un amas indéfinissable.
Il se mit à paniquer et à crier, attirant l’attention des passants effrayés. Mais personne ne semblait savoir quoi faire pour lui venir en aide. Les bras et les mains continuaient de se tordre et de se mêler, comme s’ils voulaient s’échapper de son corps. Finalement, Paul réussit à se débarrasser de ses bras et de ses mains supplémentaires et à rentrer chez lui. Il se blottit sous sa couette, épuisé par cette expérience étrange et effrayante. Il se promit de ne plus jamais sortir de chez lui, de peur que cela ne lui arrive à nouveau.
J’espère que cette histoire absurde vous a plu et vous a donné quelques idées pour imaginer un personnage avec des bras et des mains multiples qui lui échappent."
À partir de ce dernier texte, j’ai demandé à dall-e 2 d’imaginer (de produire l’image, de ce que chatGPT avait décrit). En ce sens, il s’est agi de libérer l’imagination artificielle d’une projection mimétique du sujet humain. Comme si l’IA était une machine célibataire, produisant par elle-même, dans une sorte d’auto-référentialité son propre monde. Ce qui ressort, c’est que dès qu’on s’interroge sur les processus de liaison internes qui se déroulent dans les processus de construction de l’IA, et donc qui sont au coeur de l’induction, on s’aperçoit, que l’imagination artificielle n’est pas mimétique mais produit un monde qui pour l’homme est aberrant, où ne sont respectés ni les lignes ou points de fuite, ni les logiques organiques ou corporelles, ni les perspectives ou les proportions.
Ce qui signifie que le flux d’images que nous suivons et qui sont faites par les IA sont le résultat de stéréotypes promptologiques et ontologiques qui brident les émergences de l’espace latent et réduisent le possible à la mémoire de nos images.
August 1, 2022 · category article, intelligence artificielle, photographie, [théorie], [une]

The happening est une série de photographies réalistes que j’ai réalisée avec l’IA DALL-E 2, à laquelle j’ai eu accès en juillet 2022. Beaucoup de questions surgissent avec son emploi, que je compte poser régulièrement à l’aide de ces petits articles que je rédige.
Ici ce qui m’interroge, c’est la relation entre le photo-réalisme et la question de la causalité. Dans notre réel, toute image que nous captons, donc toute photographie, est liée à une chaine de causalité. Lorsque je vois par exemple une rue de Paris, de San Paolo ou de L.A avec des passants, chaque être, chaque objet est impliqué dans la photographie selon un schème temporel et causal. Avec les réseaux sociaux, et la multiplication des micro-vidéos type tik-tok, nous sommes submergés par des images qui reposent sur des micro-actions. Même un paysage, lorsqu’il est photographié est lié à une causalité : celle qui dot que celui qui photographie est en voyage, en vacances, en week-end, etc…
 The happening est une série de photographies réalistes d’un événement. Mais quelle est la causalité dans l’image. Nous voyons une foule photographier quelque chose, mais nous ne savons pas quoi. Il y a une causalité qui est celle du prompt (le texte qui est donné à DALL-E 2), prompt que je tords toujours pour que le résultat déborde l’attendu descriptif, mais il n’y a pas de causalité interne à l’image. En travaillant sur une imprévisibilité du rendu, je brise la possibilité référentielle et réelle dans le rendu. Ceci peut se faire en interrogeant les limites des possibles de rendu de DALL-E 2. Si Etienne Mineur par exemple, a très bien vu en quel sens certaines catégories sont hyper stéréotypées et faciles à représenter pour DALL-E 2, il est possible de faire l’inverse questionner les limites du rendu d’objets, d’associations. Ce qui demande de questionner tout à la fois la logique d’assemblage grammatical du moteur, la nature des banques d’images ayant servi pour le dataset et enfin les restrictions introduites moralement par l’équipe de open-ai.
The happening est une série de photographies réalistes d’un événement. Mais quelle est la causalité dans l’image. Nous voyons une foule photographier quelque chose, mais nous ne savons pas quoi. Il y a une causalité qui est celle du prompt (le texte qui est donné à DALL-E 2), prompt que je tords toujours pour que le résultat déborde l’attendu descriptif, mais il n’y a pas de causalité interne à l’image. En travaillant sur une imprévisibilité du rendu, je brise la possibilité référentielle et réelle dans le rendu. Ceci peut se faire en interrogeant les limites des possibles de rendu de DALL-E 2. Si Etienne Mineur par exemple, a très bien vu en quel sens certaines catégories sont hyper stéréotypées et faciles à représenter pour DALL-E 2, il est possible de faire l’inverse questionner les limites du rendu d’objets, d’associations. Ce qui demande de questionner tout à la fois la logique d’assemblage grammatical du moteur, la nature des banques d’images ayant servi pour le dataset et enfin les restrictions introduites moralement par l’équipe de open-ai.
L’événement dont nous avons une trace n’a ni passé ni futur, car l’image n’a pas de causalité historique, ou encore toute causalité narrative de l’image est extérieure à sa fabrication. The happening met le spectateur de l’image face à une temporalité en suspension du point de vue de la causalité temporelle. L’IA ne construisant aucunement
Ce point est une différence majeure avec la photographie ou bien encore avec l’illustration, au sens où justement la production de l’image étant déléguée à un processus technique, celui-ci n’implique pas la construction du sens de l’image. Ou encore la mémoire sémiotique liée à la liaison image/texte n’est pas de l’ordre de la causalité narrative et historique, mais de la relation esthétique par contiguité, pour reprendre une distinction de Hume très utile.
Dès lors l’image produite par une IA est du point de vue de celle-ci, celle d’un présent pur de la contiguité des éléments, le temps de l’image ne se déploie pas dans le temps de l’action, mais seulement dans le temps de la relation. C’est le spectateur humain qui, selon la causalité temporelle, et la mémoire événementielle ou narrative, va s’interroger sur un chainage de l’événement.
_______________________________________
[ENGLISH]
The happening is a series of realistic photographs that I made with the DALL-E 2 AI, to which I had access in July 2022. Many questions arise with its use, which I intend to ask regularly using of these little articles that I write.
Here what questions me is the relationship between photo-realism and the question of causality. In our reality, any image we capture, therefore any photograph, is linked to a chain of causality. When I see, for example, a street in Paris, San Paolo or L.A with passers-by, each being, each object is involved in the photograph according to a temporal and causal scheme. With social networks, and the proliferation of tik-tok type micro-videos, we are overwhelmed by images that are deposited on micro-actions. Even a landscape, when it is photographed, is linked to a causality: the one that points out that the photographer is on a trip, on vacation, on a weekend, etc…
 The happening is a series of realistic photographs of an event. But what is the causality in the picture. We see a crowd photographing something, but we don’t know what. There is a causality which is that of the prompt (the text which is given to DALL-E 2), a prompt which I always twist so that the result overflows the descriptive expectation, but there is no internal causality to the prompt. ‘image. By working on an unpredictability of rendering, I break down the referential and real possibility in rendering. This can be done by questioning the limits of the possible rendering of DALL-E 2. If Etienne Mineur for example, has seen very well in what sense certain categories are hyper stereotyped and easy to represent for DALL-E 2, it is possible to doing the opposite questioning the limits of the rendering of objects, of associations. This requires questioning both the grammatical assembly logic of the engine, the nature of the image banks used for the dataset and finally the restrictions morally introduced by the open-ai team.
The happening is a series of realistic photographs of an event. But what is the causality in the picture. We see a crowd photographing something, but we don’t know what. There is a causality which is that of the prompt (the text which is given to DALL-E 2), a prompt which I always twist so that the result overflows the descriptive expectation, but there is no internal causality to the prompt. ‘image. By working on an unpredictability of rendering, I break down the referential and real possibility in rendering. This can be done by questioning the limits of the possible rendering of DALL-E 2. If Etienne Mineur for example, has seen very well in what sense certain categories are hyper stereotyped and easy to represent for DALL-E 2, it is possible to doing the opposite questioning the limits of the rendering of objects, of associations. This requires questioning both the grammatical assembly logic of the engine, the nature of the image banks used for the dataset and finally the restrictions morally introduced by the open-ai team.
The event of which we have a trace has neither past nor future, because the image has no historical causality, or any narrative causality of the image is external to its fabrication. The happening puts the spectator of the image in front of a temporality in suspension from the point of view of temporal causality. AI not building at all
This point is a major difference with photography or even with illustration, in the sense that precisely the production of the image being delegated to a technical process, this one does not imply the construction of the meaning of the image. Or again, the semiotic memory linked to the image/text link is not of the order of narrative and historical causality, but of the aesthetic relationship by contiguity, to take up a very useful distinction from Hume.
Therefore the image produced by an AI is from its point of view, that of a pure present of the contiguity of the elements, the time of the image does not unfold in the time of the action, but only in the time of the relationship. It is the human spectator who, according to temporal causality, and event or narrative memory, will wonder about a chaining of the event.


July 6, 2022 · category article, intelligence artificielle, [texte], [théorie], [une]

Cela fait maintenant un an que se répandent sur internet et surtout les réseaux sociaux, des créations visuelles générées par IA (Intelligence artificielle) selon le modèle du CLIP (Contrastive Language–Image Pre-training), à savoir, d’un énoncé (prompt) générant une image. Plusieurs types de logiciels on été donnés de VQGAN-clip,à pitty, de disco-diffusion à Dall.
Il est possible maintenant de réfléchir à une forme de typologie des emplois. Notamment, parce que des créateurs comme Grégory Chatonsky, Yann Minh ou bien Etienne Mineur, entre autres, ont eux-même définis les usages qu’ils en faisaient.
 L’usage majeur qui est fait de ce type d’IA fait ne tient pas tant à la recherche de l’imprédictibilité du résultat, mais comme l’exprime parfaitement Yann Minh, à la substitution d’une incompétence par une compétence ordonnée à la génération de l’IA. L’IA vient remplacer une praxis que ne possède pas le créateur afin de permettre une poiesis de l’image : la capacité à illustrer. L’IA est pensée dès lors comme prothèse, augmentation, médiation. La recherche tend à créer le plus possible selon ce que recherche l’imagination du créateur : l’IA est déterminée comme illustratrice, exécutante. C’est en ce sens que Yann Minh crée les personnages de ses romans, leur donne visage.
L’usage majeur qui est fait de ce type d’IA fait ne tient pas tant à la recherche de l’imprédictibilité du résultat, mais comme l’exprime parfaitement Yann Minh, à la substitution d’une incompétence par une compétence ordonnée à la génération de l’IA. L’IA vient remplacer une praxis que ne possède pas le créateur afin de permettre une poiesis de l’image : la capacité à illustrer. L’IA est pensée dès lors comme prothèse, augmentation, médiation. La recherche tend à créer le plus possible selon ce que recherche l’imagination du créateur : l’IA est déterminée comme illustratrice, exécutante. C’est en ce sens que Yann Minh crée les personnages de ses romans, leur donne visage.
Dans cette démarche l’imprédictibilité de ce qui survient n’est pas recherchée pour elle-même, elle n’est pas questionnée en tant que processus, même si elle n’est pas non plus ignorée, elle est considérée comme un moyen qui doit tout à la fois surprendre et obéir à l’horizon fixé par le prompt. La puissance propre à l’IA doit correspondre à une attente conceptuelle (celle du prompt) du créateur. Certes, il y a coopération, mais le créateur reste dans la logique du pilotage qui commande une exécution. L’IA est alors un instrument, dont on est pas interrogél’être propre. On est dans une logique proprement cybernétique, au sens que lui confère Aristote originellement : celle du commandement.
Une seconde démarche, parait être davantage celle de Grégory Chatonsky par exemple : celle de l’imprédictibilité du résultat du à l’espace latent de l’IA. Dans le prolongement de ses recherches, ce qu’il questionne n’est pas tant la représentation ou le résultat surréaliste (même si ce terme a été présent et déterminant dans ses premières recherches) que certaines formes de mutation de la forme propres à l’imagination machine plus que l’imaginaire machine. Cette distinction à mon sens est nécessaire. La première démarche recherche l’imaginaire machine, à savoir le résultat du processus. Alors que cette deuxième démarche dans laquelle, je me situe aussi, questionne l’imagination artificielle ou plus précisément l‘imaginer artificiel : le processus et les mécanismes de la machine en tant qu’elle génère de l’image. Comment est constitué un dataset ? Comment se fabrique à partir de bruit de perlin ou bien d’autres images par exemple une image par un processus de GAN (Generative adversarial networks) ? Quelle différence y a t il entre recombiner des formes et constituer une forme par approximation statistique ? Il ne s’agit plus seulement d’utiliser l’IA en tant qu’outil, mais de se questionner en relation à ce qu’elle pose comme réalité algorithmique.
Pour ma part c’est ce qui m’avait amener – à partir de mes propres recherches – à réfléchir sur la question de la différence de la mémoire entre celle de l’IA et celle de l’être humain et à réfléchir sur l’impossibilité du corps ou encore une nouvelle forme d’organologie, au sens où la mémoire la machine ne me semblait aucunement liée à une expérience de corps (Leib) mais à une la computation statistique de l’apprentissage profond. C’est en ce sens que je posais davantage la question du pararéalisme de la création de l’IA, que celle du surréalisme. Ce sur que semble aussi indiqué Grégory Chatonsky par exemple dans cet article où il insiste sur la question du parallélisme des mondes.
Cet horizon, où une forme de dialogue avec les possibles du logiciel est instauré entre le créateur humain et l’ensemble des possibles algorithmiques, est alors ouvert à l’imprédictible de la forme en tant qu’imprédictible pour notre mémoire de monde. La notion de prompt se détache du premier usage. Le prompt ne sera plus prescription, au sens d’une intention qui commande et doit décider, mais par approximation, il questionnera la constitution tout à la fois de la réalité latente possible par le dataset (liaison entre images et catégories linguistiques), mais aussi la manière dont algorithmiquement « l’induction statistique » (Chatonsky) opère. Car en effet, il n’y a qu’à expérimenter avec un même prompt : VQGAN, DISCO ou DALL, pour s’apercevoir qu’il y a des différences spécifiques entre les trois IA, quant à la génération.
 Une troisième voie de recherche peut être établie, et elle constitue une part importante de mon travail : celle d’une accidentlité ontologique de la matière générée par l’IA. Lorsque l’on regarde les images générées, et d’autant plus avec les différents logiciels DALL qui circulent depuis peu à la suite d’open-AI, il y a une forme d’homogénéité matérielle qui n’exclue aucunement d’ailleurs une imprédictibilité de la forme. Les images se révèlent dans une forme d’unité ontologique de la matière. Certes elles peuvent être surréalistes, ou bien heroic Fantasy ou SF, mais il y a toujours une forme de simplicité ontologique de la matière, une réduction de la différence. Je n’ai quasi jamais observé de complexité ontologique de la matière dans les créations faites par les IA. Chaque image semble obéir à une détermination qui commande l’ensemble du rendu. C’est ce qui ressort d’ailleurs parfaitement avec les lettrages d’Etienne Mineur et qu’il a lui-même remarqué : chaque lettrage est fait dans un style : mais ce style est d’abord et avant tout une forme d’homogénéité de la matière, de la texture.
Une troisième voie de recherche peut être établie, et elle constitue une part importante de mon travail : celle d’une accidentlité ontologique de la matière générée par l’IA. Lorsque l’on regarde les images générées, et d’autant plus avec les différents logiciels DALL qui circulent depuis peu à la suite d’open-AI, il y a une forme d’homogénéité matérielle qui n’exclue aucunement d’ailleurs une imprédictibilité de la forme. Les images se révèlent dans une forme d’unité ontologique de la matière. Certes elles peuvent être surréalistes, ou bien heroic Fantasy ou SF, mais il y a toujours une forme de simplicité ontologique de la matière, une réduction de la différence. Je n’ai quasi jamais observé de complexité ontologique de la matière dans les créations faites par les IA. Chaque image semble obéir à une détermination qui commande l’ensemble du rendu. C’est ce qui ressort d’ailleurs parfaitement avec les lettrages d’Etienne Mineur et qu’il a lui-même remarqué : chaque lettrage est fait dans un style : mais ce style est d’abord et avant tout une forme d’homogénéité de la matière, de la texture.
Cette homogénéité à mon sens provient de deux spécificités : la forme est privilégiée par rapport à la matière au niveau du prompt. Et deuxièmement, l’IA n’est pensée que comme un simple outil d’exécution, une application, et non pas selon une forme d’expérimentation de ses possibles de texture. C’est en ce sens que beaucoup de création par IA vont même spécifier la référence à un artiste ou bien un mouvement artistique pour créer le rendu. Ce qui est permis spécifiquement avec VQGAN, Disco Diffusion ou bien Pitty entre autres.
Il est évident que pour créer au sein d’une seule image une variation matérielle créant une véritable hétérogénéité, il s’agit de penser l’IA non plus comme une simple application, mais comme un ensemble de potentialités au niveau programmation avec lesquelles il faut entrer en dialogue afin d’en comprendre certains mécanismes, notamment quant à son travail de rendu. Il s’agit de comprendre comment ’opèrent entre autres les différents settings de matrice de rendus (vitB32, vitB16, RN50), de jouer avec, la notion de récurrence, etc… Mais aussi comment s’établit la logique de prompt, non plus du point de vue de la forme mais du possible de la texture et ainsi de laisser apparaître dans ce dialogue avec les potentialités de la machine des possibles, non pas de formes mais de matières. C’est en grande partie la direction que je tente de suivre en la liant la deuxième démarche décrite.
——————————————————————————————————————
It’s been a year now that visual creations generated by AI (Artificial Intelligence) according to the CLIP (Contrastive Language–Image Pre-training) model have been spreading on the Internet and especially on social networks, namely, a statement (prompt ) generating an image. Several kinds of software were donated from VQGAN-clip, to pitty, from disco-diffusion to Dall. It is now possible to think about a form of job typology. In particular, because creators like Grégory Chatonsky, Yann Minh or even Etienne Mineur, among others, have themselves defined the uses they made of it.
The major use that is made of this type of AI is not so much the search for the unpredictability of the result, but as Yann Minh perfectly expresses it, the substitution of an incompetence by a skill ordered to the generation of AI. AI comes to replace a praxis that the creator does not have in order to allow a poiesis of the image: the ability to illustrate. AI is therefore thought of as a prosthesis, augmentation, mediation. Research tends to create as much as possible according to what the creator’s imagination seeks: AI is determined as an illustrator, an executor. It is in this sense that Yann Minh creates the characters of his novels, gives them a face.
In this approach, the unpredictability of what happens is not sought for itself, it is not questioned as a process, even if it is not ignored either, it is considered as a means which must both surprising and obeying the horizon fixed by the prompt. The power specific to the AI ​​must correspond to a conceptual expectation (that of the prompt) of the creator. Admittedly, there is cooperation, but the creator remains in the logic of piloting which commands an execution. AI is then an instrument, whose very being we are not questioned. We are in a strictly cybernetic logic, in the sense originally given to it by Aristotle: that of command.
A second approach, seems to be more that of Grégory Chatonsky for example: that of the unpredictability of the result due to the latent space of AI. In the extension of his research, what he questions is not so much the representation or the surrealist result (even if this term was present and determining in his first research) as certain forms of mutation of the form specific to the machine imagination more than machine imagination. This distinction, in my opinion, is necessary. The first approach seeks the machine imaginary, namely the result of the process. While this second approach in which I also find myself, questions the artificial imagination or more precisely the artificial imagination: the process and the mechanisms of the machine as it generates the image. How is a dataset made? How is it made from pearl noise or other images, for example an image by a GAN process (Generative adversarial networks)? What is the difference between recombining shapes and constituting a shape by statistical approximation? It is no longer just a question of using AI as a tool, but of questioning oneself in relation to what it poses as algorithmic reality.
For my part, this is what led me – from my own research – to reflect on the question of the difference in memory between that of AI and that of human beings and to reflect on the impossibility of the body or even a new form of organology, in the sense that the memory the machine seemed to me in no way linked to an experience of the body (Leib) but to a statistical computation of deep learning. It is in this sense that I posed more the question of the pararealism of the creation of AI, than that of surrealism. This is what Grégory Chatonsky also seems to indicate, for example in this article where he insists on the question of the parallelism of the worlds.
This horizon, where a form of dialogue with the possibilities of the software is established between the human creator and all the algorithmic possibilities, is then open to the unpredictability of the form as unpredictable for our memory of the world. The notion of prompt stands out from the first use. The prompt will no longer be a prescription, in the sense of an intention that commands and must decide, but by approximation, it will question the constitution both of the latent reality possible by the dataset (link between images and linguistic categories), but also the way in which algorithmically “statistical induction” (Chatonsky) operates. Because indeed, you only have to experiment with the same prompt: VQGAN, DISCO or DALL, to realize that there are specific differences between the three AIs, as far as generation is concerned.
A third way of research can be established, and it constitutes an important part of my work: that of an ontological accidentality of matter generated by AI. When we look at the images generated, and all the more so with the various DALL software programs which have recently been circulating following open-AI, there is a form of material homogeneity which in no way excludes a unpredictability of form. The images are revealed in a form of ontological unity of matter. Certainly they can be surreal, or heroic fantasy or SF, but there is always a form of ontological simplicity of matter, a reduction of difference. I have almost never observed any ontological complexity of matter in the creations made by AIs. Each image seems to obey a determination that controls the whole rendering. This is what comes out perfectly with the lettering of Etienne Mineur and which he himself noticed: each lettering is done in a style: but this style is first and foremost a form of homogeneity material, texture.
This homogeneity in my opinion comes from two specificities: the form is privileged compared to the material at the level of the prompt. And secondly, AI is only thought of as a simple execution tool, an application, and not as a form of experimentation with its possible textures. It is in this sense that many AI creations will even specify the reference to an artist or an artistic movement to create the rendering. What is allowed specifically with VQGAN, Disco Diffusion or Pitty among others.
It is obvious that to create within a single image a material variation creating a real heterogeneity, it is a question of thinking of AI no longer as a simple application, but as a set of potentialities at the programming level with which it is necessary to enter into a dialogue in order to understand certain mechanisms, in particular with regard to its rendering work. It is a question of understanding how the different rendering matrix settings (vitB32, vitB16, RN50) operate, among other things, to play with, the notion of recurrence, etc… But also how the logic of prompt is established, either from the point of view of the form but of the possible of the texture and thus to let appear in this dialogue with the potentialities of the machine of the possibilities, not of forms but of materials. This is largely the direction I am trying to follow by linking it to the second approach described.
May 15, 2022 · category article, intelligence artificielle, [texte], [une]

Tous les jours 350 millions de photos sont publiés sur facebook. Plus de 240 milliards d’images ont été ainsi accumulées par la plateforme depuis sa création. Les réseaux sociaux ont accéléré à la fois la production des images numériques et d’autre par leur publication, leur partage, leur diffusion, leur duplication.
Dans leur article publié dans AOC, Gwenola Wagon et Stéphane Degouttin soulignent avec pertinence en quel sens les imaginaires des images diffusées, de l’open-space à l’image érotico-porno, du portrait à la vue d’ensemble, correspondent à des imaginaires reliés à des stocks d’image, à « une hygiène de l’image », « une stratégie d’évidage de l’image ». Ainsi les images viendraient recouvrir le réel par leur esthétique clean, par leur codification apriori, effaçant les aspérités du réel, et ce qu’elles engagent comme problématiques (sociales, politiques, etc) en faveur d’une vision édulcorée, adoucie, anesthésiée.
Se pose cependant la question de savoir pour qui sont destinées ces images ? En quel sens, les réseaux sociaux demandent que soient postées des images, sachant que les images stockées exigent de la place sur des servers donc des coûts réels et de la place matérielle.
Mon hypothèse, c’est que l’image prise dans une dialectique qui définit sa fin, ne correspond plus réellement à ce qu’elle était traditionnellement, mais qu’elle est immédiatement autre chose, à savoir un déchet qui est conçu médiatement pour être recyclé.
Intentionnellement, du point de vue de la conscience humaine, lorsque l’on poste une image, c’est pour qu’elle soit vue. C’est ce qui tient au désir. Et c’est ce désir de reconnaissance médiatisée de soi que stimulent les stratégies relationnelles des réseaux sociaux. J’appelle la profondeur de l’image, ce qui amène une image à nous retenir dans son temps, dans ses plis, dans sa matérialité, dans son apparaître (aiesthesis). La profondeur d’une image n’est pas ainsi une dimension matérielle, mais temporelle.
Ce que le créateur d’une image, par exemple d’un tableau peut souhaiter c’est que son image retienne l’attention. La dimension du regard tient au temps et c’est dans ce temps que l’image affecte.
Or, les réseaux sociaux ont développé une logique de flux tendu pour les informations ou images qui leur sont envoyées. L’image n’est plus pensée selon une logique de profondeur mais de transmissibilité et de stimuli rapides. Ce n’est plus la qualité de l’image qui est primordiale, mais la quantité de partage et de like. Le like et le partage ne reposent pas sur une analyse qualitative mais sur d’autres logiques liées à des processus algorithmiques : la fréquence de post, le réseau interconnecté avec celui qui poste. Dès lors l’image est pensée en tant que potentialité de like et elle exige immédiatement d’être dépassée dans la prochaine image postée. La reconnaissance n’existe que dans l’enchainement des publications. Les publications ne sont pas pensées comme liées, mais à chaque fois comme des objets autonomes. Cela se voit aussi bien par des traits spécifiques dans les créations vidéos : des mini-scénarios, d’une durée courte, sans lien avec les précédentes créations. Les réseaux sociaux sont ainsi des flux de points qui doivent se succéder indéfiniment. L’épaisseur temporelle doit être réduite le plus possible.
La logique de flux fait, et ici nous je rejoins totalement GW SD que l’image doit correspondre avec une esthétique du réseau. Cette logique de mimétisme, de mème (Dawkins), est une des clés pour réussir à augmenter la fréquence de like et de transmissibilité d’une image. Se développe ainsi une forme d’académisme de l’image, de modalité de la répétition dans une différence qui doit se nier d’une certaine manière.
L’image n’attire plus l’attention, elle entre en écho avec un déjà vu.
Ce que j’appelle l’image-déchet, est ainsi l’image conçue selon l’intentionnalité des promoteurs des réseau sociaux non plus comme devant avoir une forme d’épaisseur temporelle, mais étant immédiatement pensée selon sa logique de recyclage. Le but des réseaux sociaux tient à l’accélération des publications, en vue d’un stockage-recyclage de données.
Nous le savons, nos informations, qu’elles soient textuelles, picturales, vidéos ou audios, entrent toutes dans des bases de données (big data) qui elles-mêmes servent à alimenter des processus d’apprentissage pour des intelligences artificielles.
Le but des réseaux sociaux n’est pas l’attention portée par les humains. Cette attention n‘est qu’une médiation, en vue d’une autre fin. L’attention humaine doit même être la plus courte possible pour une image, quelqu’elle soit. En effet nous pourrions imaginer d’une manière absurde, une image qui retiendrait absolument l’attention, qui impossibiliserait toute autre image, cela anéantirait toute logique de réseau social. Nous serions alors dans une perspective à la Borgès plus qu’à la Meta ou la Google.
Au contraire les images doivent être suffisamment volatiles, pour qu’elles se succèdent sans que nous nous y arrêtions. Certes, stratégiquement, il est toujours utile pour cette logique de mettre en évidence des flux qui se démarquent. Mais ils ne sont publicitairement conçus que comme des stimuli pour inciter tout un chacun à poster.
Les images ne nous sont plus vraiment adressées. Elles ne sont plus destinées au regard humain, mais elles sont envoyées à des IA. Là aussi l’image n’est pas pensée dans une logique d’hyper-production comme réalité, mais elle est médiation pour saisir à partir d’intelligences artificielles, des informations qui ne concernent pas l’image en propre. L’image-déchet est ainsi une image qui sert de matière à recycler pour des stratégies aussi bien commerciales, politiques, sociologiques qu’esthétique. Ce qui compte n’est pas l’image en tant qu’entité, mais l’image en tant que multiplicité de données exploitables.
Lorsque l’on crée avec une IA (par exemple les systèmes CLIP), la création de l’image est le résultat du recyclage de nos images qui ont été injectées dans des datasets et analysées grâce à du deep learning. La création à l’aide d’IA se caractérise ainsi comme une forme qui se constitue à partir de potentialités qui sont tirées de l’image-déchet. Ce que nous voyons comme résultat est ainsi tout à la fois ressemblant (car issu de données élémentaires d’images pré-existantes) et dissemblabes (au sens où l’IA n’est pas dans une mimésis de perception, mais dans une mimésis par statistique à partir d’analyses de données).
_______________________________________________
Every day 350 million photos are published on facebook. More than 240 billion images have been accumulated by the platform since its creation. Social networks have accelerated both the production of digital images and others through their publication, sharing, dissemination, duplication.
In their article published in AOC, Gwenola Wagon and Stéphane Degouttin pertinently underline the sense in which the imaginaries of the images disseminated, from the open-space to the erotic-porn image, from the portrait to the overview, correspond to imaginaries related to image stocks, to "an image hygiene", "a strategy of hollowing out the image". Thus the images would come to cover the real by their clean aesthetics, by their a priori codification, erasing the roughness of the real, and what they involve as problematic (social, political, etc.) in favor of a watered down, softened, anesthetized vision.
However, the question arises, for whom are these images intended? In what sense, social networks require images to be posted, knowing that the stored images require space on servers and therefore real costs and material space.
My hypothesis is that the image taken in a dialectic that defines its end, no longer really corresponds to what it traditionally was, but that it is immediately something else, namely a waste that is mediately designed to be recycled.
Intentionally, from the point of view of human consciousness, when we post an image, it is to be seen. This is what comes down to desire. And it is this desire for mediated self-recognition that the relational strategies of social networks stimulate. I call the depth of the image, which leads an image to retain us in its time, in its folds, in its materiality, in its appearing (aiesthesis). The depth of an image is thus not a material dimension, but a temporal one.
What the creator of an image, for example of a painting, may wish is that his image attract attention. The dimension of the gaze depends on time and it is in this time that the image affects.
However, social networks have developed a tight flow logic for the information or images sent to them. The image is no longer conceived according to a logic of depth but of transmissibility and rapid stimuli. It is no longer the quality of the image that is essential, but the quantity of shares and likes. The like and the sharing are not based on a qualitative analysis but on other logics linked to algorithmic processes: the frequency of posting, the network interconnected with the one who posts. From then on the image is thought of as a potentiality of like and it immediately demands to be exceeded in the next image posted. Recognition only exists in the chain of publications. The publications are not thought of as linked, but each time as autonomous objects. This can also be seen by specific features in the video creations: mini-scenarios, of short duration, unrelated to previous creations. Social networks are thus flows of points that must follow one another indefinitely. The temporal thickness must be reduced as much as possible.
The flow logic does, and here we totally agree with GW SD that the image must correspond with the aesthetics of the network. This logic of mimicry, of meme (Dawkins), is one of the keys to successfully increasing the frequency of likes and the transmissibility of an image. Thus develops a form of academicism of the image, of modality of repetition in a difference that must be denied in a certain way.
The image no longer attracts attention, it echoes with a deja vu.
What I call the image-waste, is thus the image conceived according to the intentionality of the promoters of the social networks no longer as having to have a form of temporal thickness, but being immediately thought out according to its logic of recycling. The purpose of social networks is to accelerate publications, with a view to storing and recycling data.
We know that our information, whether textual, pictorial, video or audio, all enters databases (big data) which are themselves used to feed learning processes for artificial intelligence.
On the contrary, the images must be sufficiently volatile, so that they follow one another without our stopping there. Certainly, strategically, it is always useful for this logic to highlight flows that stand out. But they are only advertised as stimuli to encourage everyone to post.
The images are no longer really addressed to us. They are no longer intended for the human gaze, but they are sent to AIs. Here too the image is not thought of in a logic of hyper-production as reality, but it is mediation to seize from artificial intelligence, information that does not concern the image itself. The waste-image is thus an image that serves as material to be recycled for commercial, political, sociological and aesthetic strategies. What counts is not the image as an entity, but the image as a multiplicity of exploitable data.
When creating with an AI (for example with CLIP systems), the creation of the image is the result of the recycling of the broadcast images that have been injected into datasets and analyzed using deeplearning. Creation using AI is thus characterized as a form that is constituted from potentialities that are drawn from the waste-image. What we see as a result is thus both resembling (because stemming from elementary data of pre-existing images) and dissimilar (in the sense that the AI ​​is not in a mimesis of perception, but in a mimesis by statistics from data analysis).
« Previous entries ·
Next entries »